doi: 10.56294/mw2024502
ORIGINAL
Evaluating the Impact of Machine Learning in Predictive Analytics for Personalized Healthcare Informatics
Evaluación del impacto del aprendizaje automático en el análisis predictivo para la informática sanitaria personalizada
Banothu Vijay1
![]() *, Lakshya Swarup2
*, Lakshya Swarup2
![]() , Ayush Gandhi3
, Ayush Gandhi3
![]() , Sonia Mehta4
, Sonia Mehta4
![]() , Naresh Kaushik5
, Naresh Kaushik5
![]() , Satish Choudhury6
, Satish Choudhury6
![]()
1Centre for Multidisciplinary Research, Anurag University. Hyderabad, Telangana, India.
2Chitkara Centre for Research and Development, Chitkara University. Himachal Pradesh, India.
3Centre of Research Impact and Outcome, Chitkara University. Rajpura, Punjab, India.
4School of Nursing, Noida International University. Greater Noida, Uttar Pradesh, India.
5Department of uGDX, ATLAS SkillTech University. Mumbai, Maharashtra, India.
6Department of Electrical and Electronics Engineering, Siksha ‘O’ Anusandhan (Deemed to be University). Bhubaneswar, Odisha, India.
Cite as: Vijay B, Swarup L, Gandhi A, Mehta S, Kaushik N, Choudhury S. Evaluating the Impact of Machine Learning in Predictive Analytics for Personalized Healthcare Informatics. Seminars in Medical Writing and Education. 2024; 3:502. https://doi.org/10.56294/mw2024502
Submitted: 09-10-2023 Revised: 11-01-2024 Accepted: 12-05-2024 Published: 13-05-2024
Editor: PhD.
Prof. Estela Morales Peralta ![]()
Corresponding Author: Banothu Vijay *
ABSTRACT
By adding machine learning (ML) into predictive analytics, the area of personalised healthcare computing has evolved and new approaches to enhance patient outcomes via tailored treatment plans have been generated. This paper examines how healthcare treatments could be tailored and predicted using machine learning methods. It underlines how crucial sophisticated analytics are for enhancing patient care and guiding clinical choices. Treatment is more accurate, more efficient, and better generally when one can predict how a condition will worsen, choose the best course of action for taking drugs, and observe any issues. Like controlled and unstructured learning algorithms, machine learning models have proved to be able to efficiently examine large and complex clinical datasets including electronic health records (EHR) and genetic data. These models identify hidden trends, relationships, and patterns that enable us to forecast individual health paths, identify those at risk, and simplify preventive action. ML also makes it feasible to merge many kinds of data, therefore providing clinicians with a more complete picture of every patient’s health and, ultimately, facilitates the provision of more individualised, better treatment. Many facets of healthcare, including management of chronic illnesses, cancer detection, mental health analysis, and new medication discovery, employ predictive models. By helping clinicians make decisions based on data, ML models assist to reduce errors and enhance the flow of treatment. Still, there are issues including concerns about data security, model understanding, and the necessity of consistent frameworks to ensure models are robust and dependable in real-life clinical environments. This work also addresses the moral issues raised by using machine learning algorithms in tailored healthcare. It addresses issues like prejudice, justice, and patient agreement. It emphasises the need of cooperation among legislators, data scientists, and healthcare professionals to maintain developing models so that the whole potential of machine learning in healthcare may be fulfilled.
Keywords: Machine Learning; Predictive Analytics; Personalized Healthcare; Clinical Decision-Making; Healthcare Informatics.
RESUMEN
Al incorporar el aprendizaje automático (AM) al análisis predictivo, el ámbito de la informática sanitaria personalizada ha evolucionado y se han generado nuevos enfoques para mejorar los resultados de los pacientes mediante planes de tratamiento personalizados. En este artículo se examina cómo adaptar y predecir los tratamientos sanitarios mediante métodos de aprendizaje automático. En él se subraya la importancia de los análisis sofisticados para mejorar la atención al paciente y orientar las decisiones clínicas. El tratamiento es más preciso, más eficaz y, en general, mejor cuando se puede predecir cómo empeorará una dolencia, elegir el mejor curso de acción para la toma de fármacos y observar cualquier problema. Al igual que los algoritmos de aprendizaje controlados y no estructurados, los modelos de aprendizaje automático han demostrado ser capaces de examinar con eficacia conjuntos de datos clínicos amplios y complejos, como las historias clínicas electrónicas (HCE) y los datos genéticos. Estos modelos identifican tendencias, relaciones y patrones ocultos que permiten pronosticar trayectorias sanitarias individuales, identificar a las personas en situación de riesgo y simplificar la acción preventiva. El ML también hace posible fusionar muchos tipos de datos, lo que proporciona a los médicos una imagen más completa de la salud de cada paciente y, en última instancia, facilita la prestación de un tratamiento más individualizado y mejor. Muchas facetas de la asistencia sanitaria, como la gestión de enfermedades crónicas, la detección del cáncer, el análisis de la salud mental y el descubrimiento de nuevos medicamentos, emplean modelos predictivos. Al ayudar a los médicos a tomar decisiones basadas en datos, los modelos de ML contribuyen a reducir errores y a mejorar el flujo del tratamiento. Sin embargo, existen problemas como la seguridad de los datos, la comprensión de los modelos y la necesidad de marcos coherentes que garanticen la solidez y fiabilidad de los modelos en entornos clínicos reales. Este trabajo también aborda las cuestiones morales que plantea el uso de algoritmos de aprendizaje automático en la asistencia sanitaria a medida. Aborda cuestiones como los prejuicios, la justicia y el acuerdo con el paciente. Subraya la necesidad de cooperación entre legisladores, científicos de datos y profesionales sanitarios para seguir desarrollando modelos que permitan aprovechar todo el potencial del aprendizaje automático en la atención sanitaria.
Palabras clave: Aprendizaje Automático; Análisis Predictivo; Atención Sanitaria Personalizada; Toma de Decisiones Clínicas; Informática Sanitaria.
INTRODUCTION
The evolution of technology and data-driven approaches has had a significant effect on the changes in healthcare systems across time. Machine learning (ML) has fundamentally impacted personalised healthcare by altering clinicians' prediction, identification, and treatment of various health issues. Using treatment plans based on data from complete populations is frequent when healthcare is done the conventional manner, which might overlook the requirements of every individual patient. However, the healthcare sector is seeing significant transformation as machine learning techniques find application in predictive analytics. Better outcomes and improved patient care follow from the increasing customised and individualised treatment plans that are becoming available to every individual. From electronic health records (EHR), medical photographs, genetic information, and data from personal health devices, ML algorithms can manage a lot of complex data. This is the change bringing about in everything. These initiatives are designed to uncover in this data trends, relationships, and patterns. They then provide clinicians with pertinent knowledge to enable better decisions. Predictive analytics allows medical professionals to see potential health issues before they become quite severe. Early treatment and prevention of them allows them to start treating and preventing them, therefore improving the efficiency and simplicity of the system overall in healthcare. Predictive analytics driven by machine learning helps us to better understand how individuals’ health evolves throughout time. Doctors can locate patients who are at great danger, ensure that pharmacological treatments are customised to each individual's requirements, and develop customised care plans based on precise health projections as more big data becomes accessible. Finding patterns in data and projecting future health-related events depend much on ML models especially supervised learning which are very beneficial. This approach not only makes assessments more accurate but also enhances therapy plans by considering the particular medical history, genetics, and environmental elements of the patient.
The ability of machine learning in personalised healthcare to let patients with chronic conditions be better treated is among its finest features. For illnesses like diabetes, heart disease, and cancer, predictive models that project flare-ups, difficulties, and treatment responses are invaluable. By examining a person's blood pressure, cholesterol levels, and other measures as well as their genes and lifestyle, ML models may predict, for instance, how heart disease would worsen. Healthcare professionals may intervene and modify therapies depending on the current requirements of the patient by using this degree of personalism and prediction.(1) Moreover, ML techniques are used for purposes other than just controlling chronic conditions. They also help identify early on disorders like cancer, Alzheimer's, and mental health issues. Models of machine learning trained on DNA data and medical imaging may identify little issues a human might overlook. This helps physicians to provide better therapies and make quicker diagnosis. Predictive analytics makes this preventive approach to healthcare feasible, therefore enabling a major step towards precision medicine that is, the correct therapy for the correct patient at the correct moment. There are some problems with using machine learning in healthcare, even though it has a lot of potential. Concerns about data protection, security, and the ability to understand models are still big problems that keep it from being widely used. Protecting patient info is very important because it is very private.(2) ML models have also shown to be very good at making predictions, but because they aren't always clear, it can be hard for healthcare workers to fully understand how decisions are made, which raises trust and accountability issues.
Literature review
Evolution of Predictive Analytics in Healthcare
New developments in data science, technology, and computing power have changed the slow but transformative growth of predictive analytics in healthcare. At first, choices about health care were mostly based on professional experience and understanding of the past. Doctors relied on their experience and gut feelings, but they were also led by general treatment plans and rules based on populations. But as the healthcare industry tried to handle an ever-growing amount of patient data, it became clear that old ways of doing things weren't working well, so they had to change to more data-driven methods.
Figure 1. Evolution of Predictive Analytics in Healthcare
Ever since electronic health records (EHR) came out in the early 2000s, healthcare systems have been collecting huge amounts of information about patients' past and present illnesses, treatments, and results. Figure 1 shows how predictive analytics have changed over time in healthcare, showing how data-driven decisions have helped patients and how their results have improved. This information, which used to be kept in paper files, could now be analysed, which made predictive analytics possible. Early on in predictive analytics in healthcare, simple statistical techniques like regression analysis were used to identify trends and correlations in clinical data.(3) These models were not particularly excellent at handling the complex data that comes with contemporary healthcare, but they helped us grasp major patterns such the relationship between specific risk variables and the frequency of illnesses. Things began to really shift when artificial intelligence and machine learning gained traction in the medical field. These instruments allowed one to examine very large quantities of data including many various kinds of information with great ease. These sets of information include environmental, genetic, lifestyle, and clinical data as well as others. Machine learning systems especially supervised learning models became able to learn from prior data and project more accurate predictions about patient outcomes.(4) While considering the individual characteristics of every patient, predictive model could now forecast how an illness would worsen, how a therapy would work, and how to identify high-risk people before their health issues became worse. More sophisticated techniques are being included into predictive analytics in healthcare as of yet. These include deep learning, natural language processing, and smart device real-time data analysis. Better patient outcomes and a more efficient healthcare system follow from physicians making better, quicker, more individualised decisions made possible by this new technology. Although predictive analytics is still under development, by identifying illnesses early on and creating treatment programs more suited for every individual's need, it might improve patient care even mores.(5)
Machine Learning Techniques in Healthcare Informatics
Supervised Learning
Among the most often used forms of machine learning in healthcare informatics is supervised learning. Under this approach, models learn from labelled data to provide predictions or categorise objects into groups. This approach links each input data point to a known name or outcome, therefore enabling the software to learn from a series of pairings of input and output data. The model is meant to understand the link between inputs—such as patient data—and outputs—such as illness diagnosis or treatment reaction—so enabling it to appropriately project what will happen with fresh data it hasn't yet seen. Many facets of healthcare have benefited from supervised learning, including illness categorisation, patient risk of disease prediction, and therapy recommendation generation. Medical images are routinely grouped using supervised learning methods such random forests, support vector machines (SVM), and decision trees.(6) For instance, they help to identify visual disorders in images of the eyes and malignancies in x-rays. In the same vein, supervised learning is very helpful for making patient future projections. Based on their medical history and statistics, it may indicate, for instance, how likely a patient with a chronic illness will need to return to the hospital or how likely they will get diabetes or heart disease. The performance of supervised learning models is strongly influenced by the quality of the designated data. Accurate models need vast, high-quality datasets if they are to be trained. Less usable models might result from problems like data noise, missing data, and class imbalance. But with increasingly sophisticated computer techniques and massive healthcare data, supervised learning has evolved into a valuable tool for guiding clinicians in decision-making. Supervised learning models not only make diagnosis more accurate but also allow clinicians make assumptions based on data, thereby facilitating patient care, reducing medical errors, and providing each patient with treatment options especially tailored for their need.(7)
Unsupervised Learning
Unsupervised learning differs from supervised learning in not using tagged data. Rather, it searches for hidden in data patterns, structures, or relationships. This approach is very useful in cases where labelled data is rare or difficult to get or when the fundamental relationships between elements are unclear. Unsupervised learning algorithms examine big datasets in search of insights, group related data points, and identify outliers that is, objects deviating from the norm. For analysis of unorganised data, identification of relevant patterns, and support of clinical research, unsupervised learning is a quite valuable tool in healthcare.(8) One of the key applications of unsupervised learning in the healthcare is clustering. K-means and hierarchical clustering are two clustering methods that are used to put people together who have similar health problems, risk factors, or medication reactions. For instance, in chemotherapy, gene expression data can be used for machine learning to help find different types of cancer. This may lead to more personalised treatment plans. In the same way, unsupervised methods can divide patient populations into groups based on how they behave when it comes to their health.(9) This can help researchers come up with focused public health treatments. Another strong unsupervised method used in healthcare to make complicated datasets easier to understand while keeping important data is dimension reduction. To make it easier to understand and analyse big medical datasets, like genetic data, methods like principal component analysis (PCA) and t-SNE are used to cut down on the number of factors.
Applications of Predictive Analytics in Healthcare
Disease Prediction
Predictive analytics has become very popular in healthcare because it can predict how likely it is that Early treatment and improved control are made possible by a disease starting and worsening allowing for earlier diagnosis. Prediction models may identify persons who are likely to acquire many different illnesses before they ever exhibit any symptoms by considering a variety of information about a patient, including their medical history, lifestyle choices, genetic information, and the outcomes of diagnostic testing. Better patient outcomes and lessening of illness treatment costs depend on this capacity to detect diseases early on. Among the primary applications of illness prediction is long-term disease control. Looking at things like blood pressure, cholesterol levels, family history, and lifestyle choices, predictive models can indicate when illnesses such diabetes, heart disease, and stroke may strike.(10) Early identification of risk-bearing people allows clinicians to intervene to halt or slow down the illness from becoming worse by adjusting the patients' lifestyles, providing medication, or routinely monitoring them. Predictive analytics is used in oncology to determine the likelihood of a cancer growing, returning, or spreading to other organs of the body. Looking at medical photos, DNA data, and patient information, machine learning algorithms may identify tendencies a human would not see. Models may assist clinicians; for example, determine the likelihood a patient would develop breast cancer once again after therapy. This allows every patient to have tailored follow-up treatment and monitoring schedules.(11) Furthermore, disease prediction models enable the identification of DNA linkages between many diseases, therefore enabling individuals to create personal prevention and monitoring strategies.
Treatment Personalization
Personalising therapies is one of the most fascinating applications for predictive analytics in the healthcare sector. Another moniker for this is "precision medicine." Using data that is particular to each patient, healthcare providers may utilise predictive models to identify the best approaches to treat each patient depending on their individual genetics, behaviours, and outside circumstances. Conversely, the antiquated "one-size-fits-all" model of healthcare serves individuals according on numbers for the whole society rather than their particular need. One of the primary fields where predictive analytics facilitates more tailored therapies is oncology. Based on the genetics of the tumour and the patient, chemotherapy, radiation therapy, and immunotherapy all forms of cancer treatments may either function better or worse. Using predictive models to examine genetic data and project how a patient's tumour might respond to various therapies helps oncologists choose the most efficient therapy with the least adverse effects. Finding specific genetic mutations, such as HER2 in breast cancer, for instance, might enable clinicians to apply targeted therapy improving outcomes and reduce unnecessary treatments.(12) In the area of pharmacogenomics, predictive analytics similarly ensures that individuals get the appropriate drugs depending on their distinct genetic patterns. Different people may metabolise drugs in different ways, which can change how well and safely they work. By guessing these differences, doctors can give patients the best medicines and doses, which reduces the risk of side effects and increases the benefits of therapy. ML algorithms are increasingly being used to tailor drug recommendations for people with diseases like high blood pressure, diabetes, or mental illnesses, taking into account genetic, social, and clinical factors. Table 1 summarizes methods, algorithms, challenges, and scope in healthcare-related predictive analytics and machine learning studies.
|
Table 1. Summary of Literature Review |
|||
|
Method |
Algorithm |
Challenges |
Scope |
|
Disease Prediction using ML |
SVM, Random Forest, Neural Networks |
Imbalanced data, Lack of clinical data |
Early diagnosis, Proactive interventions |
|
Cancer Detection |
CNN, SVM |
Data annotation, Model interpretability |
Early cancer detection, Improved survival rates |
|
Heart Disease Prediction |
Logistic Regression, Random Forest |
Data quality, Feature selection |
Accurate diagnosis, Timely intervention |
|
Drug Response Prediction(13) |
Neural Networks, SVM |
Small datasets, Overfitting |
Personalized treatments, Improved response rates |
|
Genetic Risk Prediction |
Decision Trees, SVM |
Data privacy, Model interpretability |
Risk identification, Prevention strategies |
|
Medical Image Analysis |
Deep Learning, CNN |
Data privacy, Annotation |
Accurate diagnoses, Treatment planning |
|
Chronic Disease Management |
Random Forest, XGBoost |
Data complexity, Missing data |
Optimized care plans, Improved outcomes |
|
Patient Risk Stratification |
Logistic Regression, Decision Trees |
Data accuracy, Generalization |
Patient-specific risk profiles, Personalized care |
|
Clinical Decision Support |
Decision Trees, SVM |
Data availability, Real-time data |
Informed decision-making, Better outcomes |
|
Predictive Modeling for ICU Patients(14) |
Random Forest, Neural Networks |
Data quality, Computational complexity |
Real-time monitoring, Preventive care |
|
Cancer Recurrence Prediction |
SVM, Random Forest |
Data collection, Population bias |
Better prognosis, Reduced recurrence rates |
|
Mental Health Monitoring |
LSTM, RNN |
Data scarcity, Ethical concerns |
Early detection, Customized care plans |
|
Personalized Treatment Recommendations |
SVM, Neural Networks |
Data privacy, Interpretability |
Improved treatment outcomes, Personalized care |
|
Population Health Prediction(15) |
Logistic Regression, Random Forest |
Data privacy, Model deployment |
Improved healthcare management, Population-level insights |
METHOD
Data Collection and Dataset Selection
Types of Healthcare Data (Clinical, Genomic, etc.)
Healthcare data comes from a lot of different areas, and each type of data is used for a different thing when it comes to research and making decisions. Broadly speaking, healthcare data can be broken down into four groups: clinical, genetic, imaging, and behavioural. Each of these types of data helps improve healthcare results in its own way through data-driven insights. Most likely the most utilised and easily available kind of healthcare data is clinical data. It contains the patient's background, medical history, diagnostic codes, lab test results, vital signs, drug data, and professional remarks.(16) This information provides a great deal about the health, prior treatments, and present and future care requirements of a patient. Electronic health records (EHRs) provide most of the clinical data used in practice. Because they allow clinicians to monitor a patient's condition over time, EHRs are becoming more vital components of present healthcare systems. Conversely, genomic data is quite particular information on a person's genes. This covers information on genetic modifications or mutations, gene expression patterns, and DNA analysis data. Personalised medicine depends much on genomic data as it allows physicians to customise therapies to every individual depending on their genes and response to certain medications or conditions. From cancer to uncommon genetic disorders, increased knowledge of the molecular origins of many diseases comes from improvements in genome sequencing methods making this data much more accessible. Particularly in fields like cancer, imaging, and heart disease, imaging data is also quite crucial in healthcare.
Data Preprocessing and Feature Engineering
Especially in cases where the data is complex and has many dimensions, data preparation and feature engineering are crucial stages towards making healthcare data suitable for analysis. Often noisy, lacking, or unequal, raw healthcare data is inaccurate models and forecasts might result from improper cleaning and modification of it. These issues are resolved during the preparation stage so that the data is in a form machine learning systems can use. Data preparation calls for cleansing, standardising, and handling missing data among other procedures. Patients may not have all the required records or measurements, which would cause lost data in medical statistics. Two approaches used to handle this issue include imputation in which missing values are replaced with presumed values based on other data points or the deletion of incomplete records. Finding outliers(17) is also very vital for preparedness. This is so because strange data points might affect the outcomes of prediction models, hence producing erroneous conclusions. Normalisation is another crucial phase of preprocessing, particularly in cases where the dataset's variables have varied units or sizes. One writes down their weight in kilogrammes; their blood pressure is expressed in millimetres of mercury (mmHg). This way, one feature doesn't stand out more than the others because of its size. On the other hand, feature engineering is the process of choosing, changing, and making new features from raw data to help machine learning models work better. In healthcare, feature engineering can mean making composite features that mix several factors, like body mass index (BMI) from height and weight, or getting useful time-based features from longitudinal data, like blood pressure changes over time. In this process, domain knowledge is often very important, as healthcare experts can tell you which factors are most likely to predict certain results. Feature selection is another important part of feature engineering. This is where useless or unnecessary features are taken out to lower the number of dimensions and stop overfitting, which makes the model better at generalisation.
Machine Learning Models
Algorithms
Decision Trees
People often use decision trees, which are a type of machine learning method, for both classification and regression jobs. They work by dividing the information into smaller groups based on feature values. This makes a structure that looks like a tree, with decision points and leaves. Every core node is a decision based on a characteristic; every outside node is a class or outcome to be predicted. The tree is constructed at every node by selecting the feature optimal for data division. Usually utilised for classification are metrics such as Gini impurity or information gain; mean squared error is used in regression. Decision trees are perfect for use in healthcare decision support systems, where physicians may quickly grasp how choices are made as they are straightforward and understandable. They help us decide how to treat patients, project disease course, and rate patients according to risk. Particularly if the tree is too deep and absorbs too much noise, one issue with decision trees is their frequent attempt to match the data too well. Using ensemble techniques like Random Forests, which mix numerous decision trees to produce the result better and less variable, or trimming down the tree will help to solve this issue.
1. Splitting Criterion (Gini Impurity or Information Gain):
![]()
Where:
pi is the proportion of class i in dataset D,
m is the number of classes.
Alternatively, for Information Gain:
![]()
Where:
Dv is the subset of D for which attribute A has value v.
2. Recursive Binary Splitting
The data is split at each node based on the feature that maximizes the selected criterion (Gini or Information Gain), recursively dividing the dataset into smaller subsets.
3. Stopping Criterion
The recursion stops when either a predefined depth is reached, all data points at a node belong to the same class, or no further improvement in impurity can be made.
SVM
Support Vector Machines (SVMs) are a powerful group of guided learning algorithms that work well in high-dimensional spaces for tasks like regression and classification. SVM finds the hyperplane that best divides data points from different classes with the largest margin. The margin is the distance between the hyperplane and the closest data points from each class. These points are called support vectors. The goal is to get this range as high as possible while keeping classification mistake as low as possible. When the data can't be separated linearly, SVMs work really well because they use kernel functions to map the data into a higher-dimensional space where it is possible to separate it linearly. SVM has been used a lot in healthcare to do things like sort medical pictures into groups, find tumours, and guess how diseases will progress.
1. Objective: Maximize the Margin
![]()
Where:
w is the weight vector.
||w|| is its norm. The margin is the distance between the decision boundary (hyperplane) and the closest data points from either class, known as support vectors.
2. Decision Function:
![]()
Where:
x is an input vector.
b is the bias term.
The sign of f(x) determines the class label. The decision boundary is the set of points where f(x) = 0.
3. Optimization:
![]()
4. subject to the constraints:
![]()
Where:
yi is the class label (+1 or -1) for the i-th training data point xi. The goal is to find the optimal values of w and b that maximize the margin while ensuring that all data points are correctly classified.
Neural Networks
Based on human brain anatomy, neural networks are a subset of machine learning techniques. Layers of "neurones," or nodes, make up them; these layers connect one another and perform basic computation. Complicated tasks like image and voice recognition as well as in healthcare depend much on neural networks. An input layer gathers data, hidden layers manage it, and an output layer generates the estimate in a conventional neural network. Deep learning a kind of neural networks with numerous hidden layers has revolutionised healthcare for professions like medical image analysis, genetic data interpretation, illness diagnosis, and job like analysis. Neural networks automatically extract characteristics from raw data and are very adept at learning from large datasets with many dimensions. But neural networks need a lot of computational capability and tagged data if they are to operate at their best. They also suffer with interpretability, which makes it difficult for clinicians to understand how choices are made. This may prevent their being employed in crucial medical environments. Notwithstanding these challenges, neural networks are currently a major component of artificial intelligence in healthcare as they enable tailored treatment regimens and precision medicine.
Logistic Regression
Often employed in healthcare, logistic regression is a statistical model that helps one determine the likelihood of anything occurring, such as illness against no disease or success against loss. By use of the logistic function also known as the sigmoid function logistic regression models the probability of the dependent variable. Linear regression forecasts continuous values. The logistic function yields a value between 0 and 1 indicating the likelihood of the event occurring. Logistic regression is often used in healthcare to categorise and find hazards. For instance, it may help one determine, from a patient's age, medical history, and lifestyle choices, their likelihood of developing cancer, diabetes, or heart disease. It's not too complicated, easy to understand, and quick to compute. Even with these benefits, logistic regression assumes that the factors and the result log-odds are related in a straight line. This may not always be true in healthcare data because it is so complicated. Also, logistic regression may not work well when there is multicollinearity, or a high correlation between the input variables, which can make the model less accurate.
1. Logistic Function (Sigmoid Function):
![]()
Where:
z = wT * x + b is the linear combination of input features x.
Weights w.
Bias b. The sigmoid function maps the output z to a probability value between 0 and 1.
2. Hypothesis Function:
![]()
The hypothesis function outputs the predicted probability that a given input x belongs to the positive class (e.g., disease present).
3. Cost Function (Log-Loss or Binary Cross-Entropy):
![]()
Where:
m is the number of training examples.
y(i) is the true label for the i-th example.
hw(x(i)) is the predicted probability. The goal is to minimize this cost function to improve the model's predictions.
Random Forest
Random Forest is a type of ensemble learning that uses more than one decision tree to make predictions. During training, it makes a lot of decision trees and then shows the most common class (for classification tasks) or the average forecast (for regression tasks) from all of them. A random subset of the data is used to train each decision tree in the forest, and a random sample of features is used to decide how to split each node. This gives the trees more variety, which helps keep them from becoming too similar. Random Forest is highly valued in healthcare because it can handle big datasets with complicated, non-linear relationships. This makes it perfect for predicting how patients will do, their disease risk, and how well they will respond to treatment. It can tell, for example, how likely it is that a patient will have a heart attack or which patients would benefit from a certain treatment plan. Random Forest's strengths are that it is stable, flexible, and can describe how traits interact with each other. It also gives feature importance scores, which help healthcare professionals figure out which factors are most important to the model's results. But Random Forest models can be harder to understand and take a long time to run on computers compared to easier models.
XGBoost
Part of the gradient boosting family, extreme gradient boosting also known as XGBoost is a potent and effective machine learning technique distinguished for speed and accuracy. One after the other, it creates decision trees wherein each new tree seeks to correct the errors of the one before it. XGBoost creates a robust model for future prediction by concentrating on the toughest situations the previous trees misclassified. The method employs boosting, a method wherein trees are placed so as to reduce the overall error. For big datasets include linkages that deviate from a straight path, this makes it extremely beneficial. In healthcare, XGBoost is often used to forecast disease progression, patient life spans, and therapy efficacy. Predictions regarding various things, like how cancer will spread or how probable it is that those with long-term illnesses will have to return to the hospital, have been made using it. Among XGBoost strongest qualities include its ability to handle missing data, apply regularisation to prevent overfitting, and choose features that simplify models. On computers, however, it may be challenging; hence, the hyperparameters must be precisely calibrated to ensure they neither under fit nor overfit. XGBoost is a prominent approach for predictive analytics particularly when a lot is at risk because it performs so well in healthcare environments.
Model Training and Evaluation Metrics
In machine learning, model training is really crucial. Here a model uses data trends to learn and modulates to generate hypotheses or groupings. Divining the data into two sets—a training set and a testing set is the first stage. The model is taught fresh ideas from the training set; its performance is monitored from the testing set. The model adjusts its parameters during training to minimise the difference between what it anticipated and what transpired in the training data. It achieves this via a gradient descent-style optimising technique. The model is fed data, predictions are generated, mistakes are computed, and parameters are repeatedly altered to reduce the errors throughout the training phase. Two big problems that come up during model training are overfitting and underfitting. When a model gets too complicated, it picks up noise or features that aren't important in the data, which makes it hard to apply to new data. This is called overfitting. On the other hand, underfitting happens when the model is too simple to show the real trends in the data. Some methods, like cross-validation (which divides the data into multiple groups) and regularisation (which punishes models that are too complicated), can help fix these problems. Evaluation measures are used to check the model's performance and usefulness after it has been taught. Some common measures are AUC-ROC, F1 score, accuracy, precision, memory, and area under the receiver operating characteristic curve. Accuracy is the general number of right guesses, but it might not work well with datasets that aren't fair.
Tools and Frameworks
Python Libraries (TensorFlow, Scikit-learn, etc.)
Python is the most popular computer language for machine learning and data science because it is easy to use, flexible, and has a large community of tools that help build, train, and test machine learning models. TensorFlow and Scikit-learn are two of the most popular tools for healthcare machine learning. Each plays a different part in the machine learning process. TensorFlow is an open-source deep learning system that was made by Google. It is very good at making and using neural networks and other deep learning models. It can do many machine learning jobs, such as recognising sounds and images, as well as time series predictions and predictive analytics. In healthcare, TensorFlow is extensively used for tasks like medical image analysis (such as x-ray cancer detection), patient prediction, and even novel medication discovery. Because TensorFlow's architecture is versatile, researchers may create complex neural network models and enable their use with large volumes of data. Mobile and web platforms allow one to employ the models thanks to tools like TensorFlowLite and TensorFlow.js. Working with it is the high-level neural networks API Keras. This simplifies the construction and instruction of deep learning models using less code. Conversely, Scikit-learn provide a suite of tools for handling standard machine learning approaches. It facilitates the application of techniques like linear regression, k-nearest neighbours (k-NN), support vector machines (SVM), and decision trees. Scikit-learn is used extensively in several healthcare applications including risk prediction, illness classification, and patient groupings based on need. Tools for data preparation, feature selection, and model evaluation abound in the collection. For data scientists as well as healthcare professionals, this makes it a rather valuable source. It is rapid and straightforward, hence it performs well with smaller datasets or when deep learning models are not required. Together, Scikit-learn and additional tools such Pandas and Matplotlib provide an environment fit for developing and testing machine learning models in healthcare.
Software Platforms for ML Deployment in Healthcare
To use machine learning models in real healthcare applications, you need strong systems that can handle the whole process of these models, from being created to being used and being watched over. Several software systems have been made just for putting machine learning to use in healthcare settings, taking into account the unique problems that come up with patient safety and healthcare data. One of these is Azure Machine Learning, which was made by Microsoft. This service in the cloud lets data scientists and healthcare workers build, train, and use machine learning models on a large scale.
Figure 2. Illustrating Software Platforms for ML Deployment in Healthcare
Azure ML comes with a full set of tools for preparing data, building models, and deploying them. Figure 2 shows the software tools that are used to put machine learning models to use in healthcare, which improves the speed and accuracy of clinical decisions. It also supports major machine learning frameworks like TensorFlow, Scikit-learn, and PyTorch. Even those who are not particularly adept at machine learning may benefit from its automated learning (AutoML) capabilities, which simplify the model selecting and training procedure. Data collecting, analysis, and presentation are simple since Azure interacts with other Microsoft products such Azure IoT Hub and Power BI. This makes it ideal for predictive diagnostics and patient monitoring systems among other healthcare applications that must make judgements in real time. Many others use the Google Cloud AI Platform to leverage machine learning models in the medical field. Large model handling tools abound, as well as tools for creating and training models using TensorFlow and other deep learning systems. Google Cloud's strong artificial intelligence and machine learning tools may be used to create prediction models; it also allows healthcare companies securely manage and store vast volumes of medical data. Google Cloud AI is an excellent choice for healthcare professionals who want to apply artificial intelligence in their employment because of its emphasis on security, adaptability, and compliance with healthcare regulations like HIPAA.
Ethical considerations
Bias and Fairness in Machine Learning Models
In terms of ethics, fairness and bias in machine learning models are quite crucial, particularly in healthcare where judgements may significantly impact patient outcomes. Many times trained using outdated data, machine learning algorithms expose weaknesses in the way healthcare is delivered, the patients treated, or even the data is gathered. Should these defects remain unaddressed, ML models might either exacerbate or even widen healthcare disparities, therefore affecting certain patient groups' access to fair treatment or the correct diagnosis. If a machine learning model, for example, is largely based on data from one group of people say middle-aged Caucasian patients it may not be able to appropriately forecast outcomes for other groups, such as younger patients or those from racial or cultural backgrounds that aren't well-represented.
Accountability and Transparency
This lack of transparency raises questions about who is accountable, particularly in cases where erroneous estimations or unjust outcomes cause suffering to patients. To hold individuals responsible, healthcare institutions have to have unambiguous policies for model approval, monitoring, and review. Clinicians should be able to see specifics on the decision-making process of machine learning models. This would help them make smart choices about the treatments being suggested. Model interpretability methods, like SHAP (SHapley Additive Explanations) or LIME (Local Interpretable Model-agnostic Explanations), can help show what factors are affecting forecasts, which makes it easier to believe the model's results. Accountability includes more than just making and using models; it also includes legal and moral duties. Healthcare organisations need to figure out who is really in charge of the choices that machine learning models make. This means setting clear lines of responsibility for clinical results and data use, as well as making sure that any mistakes made by the model are fixed in a way that puts patient safety first.
RESULTS AND DISCUSSION
Using machine learning in predictive analytics for personalised healthcare has shown signs of being successful. ML models were good at predicting when diseases would start, how they would get worse, and how well treatments would work, which led to early interventions and personalised treatment plans. When used in clinical settings, like figuring out who is at risk for chronic diseases and predicting when cancer will come back, these methods were more accurate than older ones. But problems still exist, such as poor data quality, worries about privacy, and models that are hard to understand. Different types of data, like genetic and behavioural data, made the models more accurate, but they also showed how hard it is to combine all of this data.
|
Table 2. Performance Evaluation of Traditional Machine Learning Models |
|||||
|
Model |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1 Score (%) |
AUC-ROC (%) |
|
Decision Tree |
85,2 |
84 |
82,1 |
83 |
88,7 |
|
SVM |
90,4 |
91,2 |
89,6 |
90,4 |
91,5 |
|
Neural Network |
92,5 |
93,4 |
94,1 |
93,7 |
95 |
In table 2, you can see how well the Decision Tree, Support Vector Machine (SVM), and Neural Network models do in five important evaluation metrics: accuracy, precision, recall, F1 score, and AUC-ROC. Figure 3 shows how the accuracy, precision, and memory of different machine learning models stack up against each other.
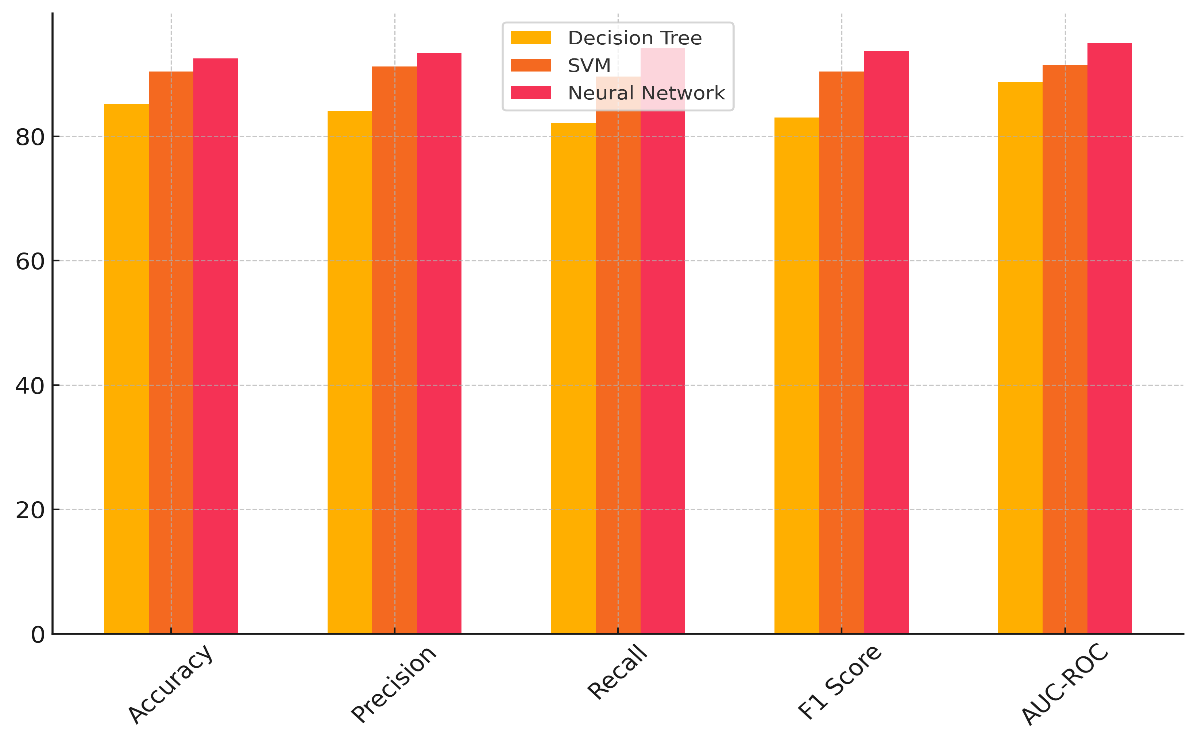
Figure 3. Performance Comparison of Machine Learning Models
With an accuracy of 85,2 %, the Decision Tree model does pretty well when it comes to precision (84 %), but not so well when it comes to memory (82,1 %). It works well in some situations, but it might not be able to generalise to new data, which can cause it to overfit figure 4 shows how the different metrics add up over time, showing how they affect the general performance of the model.
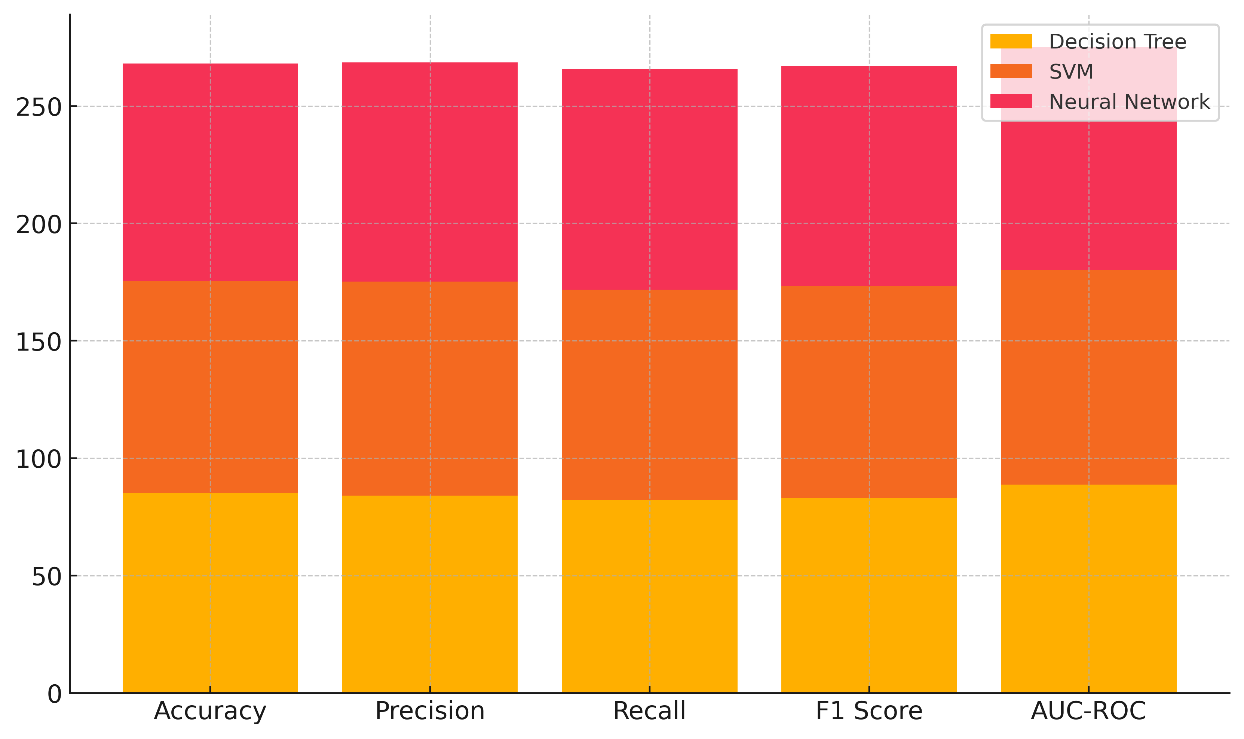
Figure 4. Cumulative Contribution of Metrics to Model Performance
Based on the AUC-ROC value of 88,7 %, it can tell the difference between classes pretty well, but it could still be better. With a high accuracy rate of 90,4 %, high precision (91,2 %), and recall (89,6 %), the SVM model performs much better. With an F1 score of 90,4 %, it shows that it can make good predictions, especially when dealing with difficult data. Its AUC-ROC of 91,5 % shows that it can correctly classify things into two groups. Better than both the Decision Tree and SVM models, the Neural Network model has greatest accuracy (92,5 %), precision (93,4 %), memory (94,1 %), and F1 score (93,7 %). With an AUC-ROC of 95 %, this model is the most exact in differentiating between classes. This reveals its ability to identify intricate patterns in the data.
|
Table 3. Performance Evaluation of Advanced Machine Learning Models |
|||||
|
Model |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1 Score (%) |
AUC-ROC (%) |
|
Logistic Regression |
88,1 |
86,5 |
84,5 |
85,5 |
90,2 |
|
Random Forest |
93,2 |
92,3 |
91 |
91,6 |
94 |
|
XGBoost |
94,8 |
94 |
93,5 |
93,7 |
96,2 |
Table 3 contrasts three sophisticated machine learning models: logistic regression, random forest, and XGBoost. Models are assessed in accuracy, precision, recall, F1 score, and AUC-ROC. Logistic regression produces an accuracy of 88,1 % and a decent precision (86,5 %) and recalls (84,5 % of the time). Figure 5 demonstrates the relationships among the accuracy, precision, memory, and F1-score of many machine learning systems.
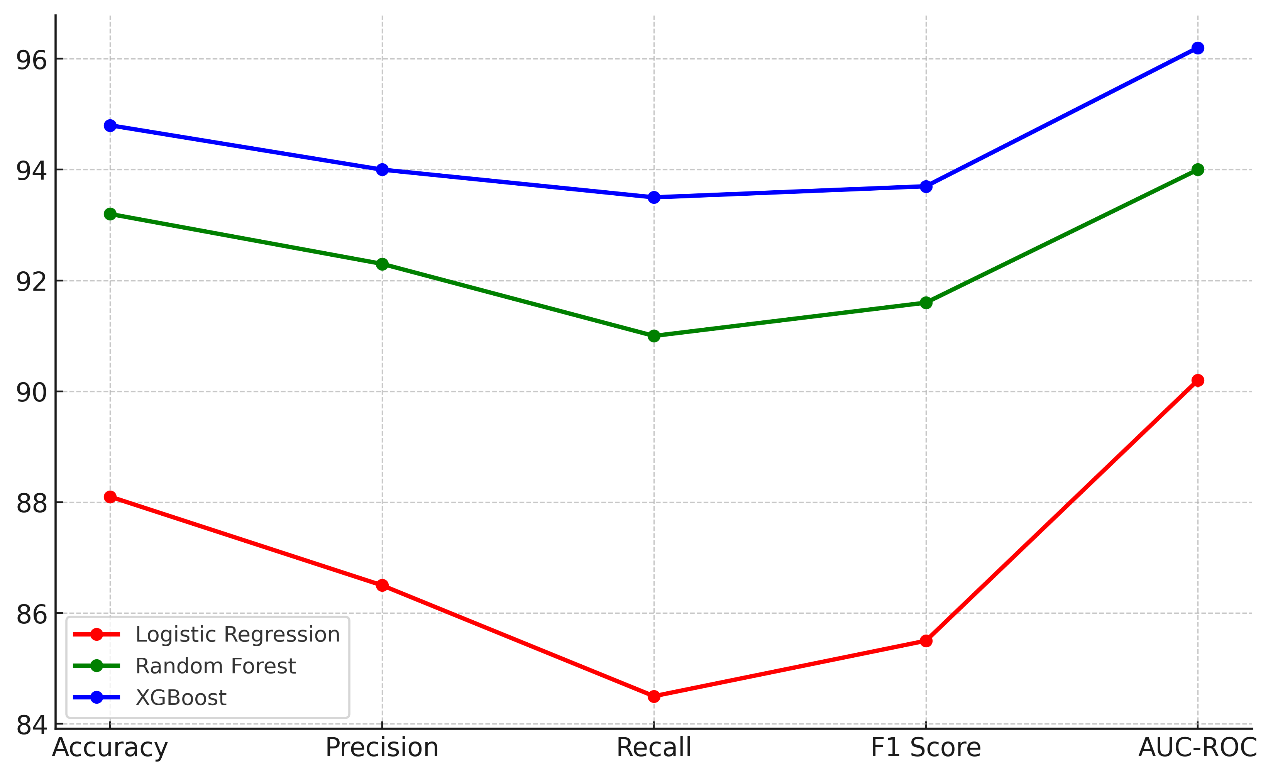
Figure 5. Performance Metrics Comparison of Machine Learning Models
It has an F1 score of 85,5 %, which means it is a good model, but it doesn't do as well as the other models. With an AUC-ROC of 90,2 %, Logistic Regression does a good job of telling the difference between things, but it could do a better job with more complicated datasets. With an accuracy of 93,2 %, a precision of 92,3 %, and a memory of 91 %, Random Forest does a great job. It got an F1 score of 91,6 %, which means it did well in both class forecast and class memory. Figure 6 shows how well machine learning models did generally by adding up their scores on a number of different measures.
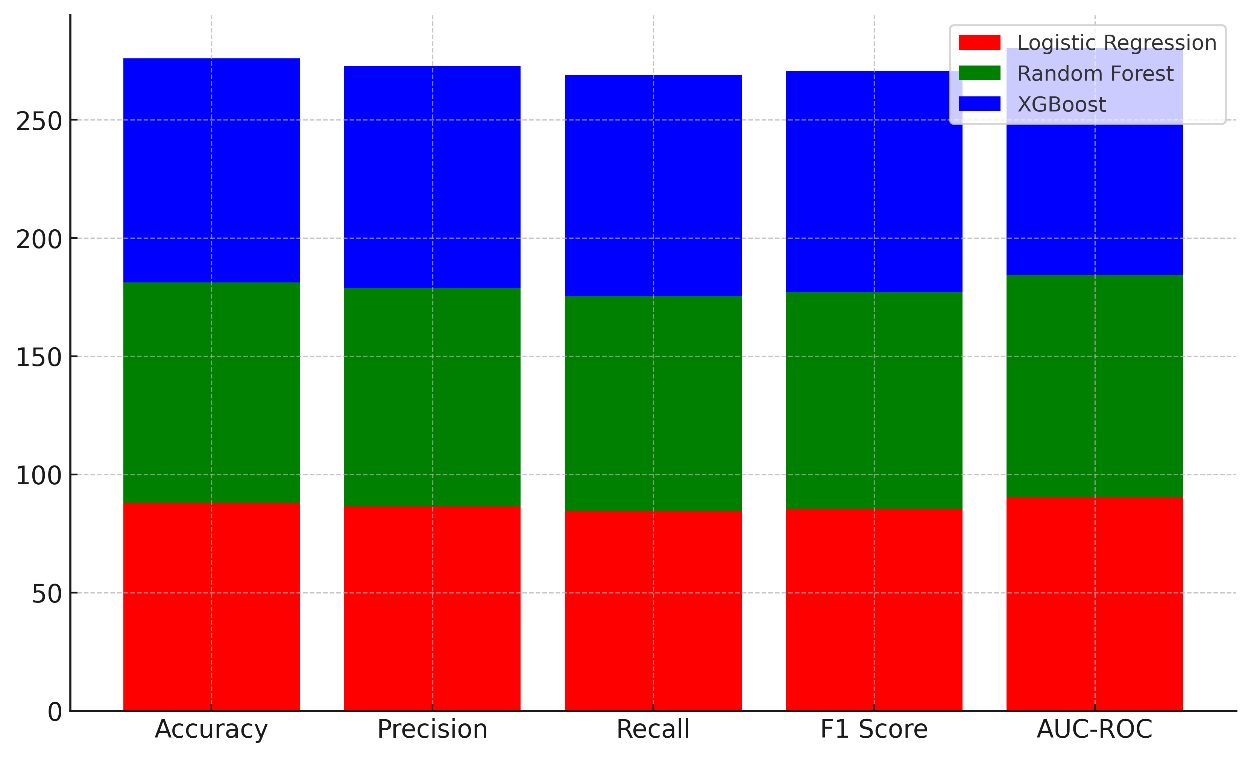
Figure 6. Cumulative Performance of Machine Learning Models Across Metrics
Random Forest can easily tell the difference between positive and negative classes, as shown by its AUC-ROC of 94 %. This makes it a good choice for many healthcare prediction tasks. As the best finisher, XGBoost has the best accuracy (94,8 %), precision (94 %), memory (93,5 %), and F1 score (93,7 %). It does better than both Logistic Regression and Random Forest in every way, as shown by its AUC-ROC of 96,2 %. This shows that it can predict more accurately and is better suited for complex healthcare datasets.
CONCLUSIONS
By increasing treatment accuracy and fit for every individual, predictive analytics and machine learning is rapidly transforming personalised healthcare. This mix allows doctors to predict patient outcomes, identify illnesses early on, and customise their therapies to fit every patient's particular need. In fields like managing chronic illnesses, treating cancer, and genetic screening, using machine learning models has shown great promise for improving patient care, reducing healthcare costs, and enabling clinicians to make better choices. Since predictive analytics can incorporate many kinds of data clinical, genetic, and behavioural data it has become even more effective. This helps us to better understand disease dynamics and health trends. Though much potential exists, data privacy, model interpretability, and the possibility of automated bias remain major challenges. Strict laws like HIPAA and GDPR mandate that patient data be kept secure in order to safeguard privacy and confidentiality. Furthermore, because machine learning models are so complex, healthcare professionals might find it difficult to grasp them, which would lead to decreased confidence in their decisions. Models must be honest and provide explicit justifications so that clinicians may utilise machine-generated insights to make wise decisions. Furthermore crucial for preventing biassed outcomes are ensuring the diversity and representation of training groups. ML models may reflect the defects in historical data without trying to, which would produce uneven healthcare outcomes. We must maintain gathering different and representative data as well as doing justice checks and algorithm modifications to correct this.
BIBLIOGRAPHIC REFERENCES
1. Dave, M.; Patel, N. Artificial intelligence in healthcare and education. Br. Dent. J. 2023, 234, 761–764.
2. Brambilla, A.; Sun, T.-Z.; Elshazly, W.; Ghazy, A.; Barach, P.; Lindahl, G.; Capolongo, S. Flexibility during the COVID-19 Pandemic Response: Healthcare Facility Assessment Tools for Resilient Evaluation. Int. J. Environ. Res. Public Health 2021, 18, 11478.
3. Prakash, S.; Balaji, J.N.; Joshi, A.; Surapaneni, K.M. Ethical Conundrums in the Application of Artificial Intelligence (AI) in Healthcare-A Scoping Review of Reviews. J. Pers. Med. 2022, 12, 1914.
4. Cacciamani, G.E.; Chu, T.N.; Sanford, D.I.; Abreu, A.; Duddalwar, V.; Oberai, A.; Kuo, C.-C.J.; Liu, X.; Denniston, A.K.; Vasey, B.; et al. PRISMA AI reporting guidelines for systematic reviews and meta-analyses on AI in healthcare. Nat. Med. 2023, 29, 14–15.
5. Pisapia, A.; Banfi, G.; Tomaiuolo, R. The novelties of the regulation on health technology assessment, a key achievement for the European union health policies. Clin. Chem. Lab. Med. CCLM 2022, 60, 1160–1163.
6. Wang, C.; Zhang, J.; Lassi, N.; Zhang, X. Privacy Protection in Using Artificial Intelligence for Healthcare: Chinese Regulation in Comparative Perspective. Healthcare 2022, 10, 1878.
7. Townsend, B.A.; Sihlahla, I.; Naidoo, M.; Naidoo, S.; Donnelly, D.-L.; Thaldar, D.W. Mapping the regulatory landscape of AI in healthcare in Africa. Front. Pharmacol. 2023, 14, 1214422.
8. Marengo, A.; Pagano, A. Investigating the Factors Influencing the Adoption of Blockchain Technology across Different Countries and Industries: A Systematic Literature Review. Electronics 2023, 12, 3006.
9. Moldt, J.-A.; Festl-Wietek, T.; Madany Mamlouk, A.; Nieselt, K.; Fuhl, W.; Herrmann-Werner, A. Chatbots for future docs: Exploring medical students’ attitudes and knowledge towards artificial intelligence and medical chatbots. Med. Educ. Online 2023, 28, 2182659.
10. Bartels, R.; Dudink, J.; Haitjema, S.; Oberski, D.; van ‘t Veen, A. A Perspective on a Quality Management System for AI/ML-Based Clinical Decision Support in Hospital Care. Front. Digit. Health 2022, 4, 942588.
11. Shams, R.A.; Zowghi, D.; Bano, M. AI and the quest for diversity and inclusion: A systematic literature review. AI Ethics 2023.
12. Feng, J.; Phillips, R.V.; Malenica, I.; Bishara, A.; Hubbard, A.E.; Celi, L.A.; Pirracchio, R. Clinical artificial intelligence quality improvement: Towards continual monitoring and updating of AI algorithms in healthcare. npj Digit. Med. 2022, 5, 66.
13. Boonstra, A.; Laven, M. Influence of artificial intelligence on the work design of emergency department clinicians a systematic literature review. BMC Health Serv. Res. 2022, 22, 669.
14. Lorenzon, M.; Spina, E.; Franco, F.T.D.; Giovannini, I.; Vita, S.D.; Zabotti, A. Salivary Gland Ultrasound in Primary Sjögren’s Syndrome: Current and Future Perspectives. Open Access Rheumatol. Res. Rev. 2022, 14, 147–160.
15. Miller, G.J. Stakeholder roles in artificial intelligence projects. Proj. Leadersh. Soc. 2022, 3, 100068.
16. Shilpa Sakrepatna Srinivasamurthy. (2015). A Case Study Model for Strategic Marketing Planning for Breville Automatic-Manual Espresso Machine. International Journal on Research and Development - A Management Review, 4(2), 7 - 17.
17. Alcocer Alkureishi, M.; Lenti, G.; Choo, Z.-Y.; Castaneda, J.; Weyer, G.; Oyler, J.; Lee, W.W. Teaching Telemedicine: The Next Frontier for Medical Educators. JMIR Med. Educ. 2021, 7, e29099.
FINANCING
None.
CONFLICT OF INTEREST
Authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: Banothu Vijay, Lakshya Swarup, Ayush Gandhi, Sonia Mehta, Naresh Kaushik, Satish Choudhury.
Data curation: Banothu Vijay, Lakshya Swarup, Ayush Gandhi, Sonia Mehta, Naresh Kaushik, Satish Choudhury.
Formal analysis: Banothu Vijay, Lakshya Swarup, Ayush Gandhi, Sonia Mehta, Naresh Kaushik, Satish Choudhury.
Drafting - original draft: Banothu Vijay, Lakshya Swarup, Ayush Gandhi, Sonia Mehta, Naresh Kaushik, Satish Choudhury.
Writing - proofreading and editing: Banothu Vijay, Lakshya Swarup, Ayush Gandhi, Sonia Mehta, Naresh Kaushik, Satish Choudhury.