doi: 10.56294/mw2024512
ORIGINAL
Enhancing Decision-Making in Public Health Informatics Using AI and Big Data Analytics
Mejora de la toma de decisiones en informática de salud pública mediante IA y análisis de macrodatos
Renuka
Jyothi S1 ![]() *,
Zuleika Homavazir2
*,
Zuleika Homavazir2 ![]() , Manoranjan Parhi3
, Manoranjan Parhi3 ![]() , Nagireddy Mounika4
, Nagireddy Mounika4 ![]() , Mithhil Arora5
, Mithhil Arora5 ![]() , Akhilesh Kalia6
, Akhilesh Kalia6 ![]() , Avir Sarkar7
, Avir Sarkar7 ![]()
1Biotechnology and Genetics, JAIN (Deemed-to-be University). Bangalore, Karnataka, India.
2Department of ISME, ATLAS SkillTech University. Mumbai, Maharashtra, India.
3Centre for Data Sciences, Siksha ‘O’ Anusandhan (Deemed to be University). Bhubaneswar, Odisha, India.
4Centre for Multidisciplinary Research, Anurag University. Hyderabad, Telangana, India.
5Chitkara Centre for Research and Development, Chitkara University. Himachal Pradesh, India.
6Centre of Research Impact and Outcome, Chitkara University. Rajpura, Punjab, India.
7Department of Obstetrics and Gynaecology, Noida International University. Greater Noida, Uttar Pradesh, India.
Cite as: Jyothi S R, Homavazir Z, Parhi M, Mounika N, Arora M, Kalia A, et al. Enhancing Decision-Making in Public Health Informatics Using AI and Big Data Analytics. Seminars in Medical Writing and Education. 2024; 3:512. https://doi.org/10.56294/mw2024512
Submitted: 11-10-2023 Revised: 13-01-2024 Accepted: 14-05-2024 Published: 15-05-2024
Editor: PhD.
Prof. Estela Morales Peralta ![]()
Corresponding Author: Renuka Jyothi S *
ABSTRACT
In public health computing, artificial intelligence (AI) and big data analytics together provide a wealth of fresh approaches to handle significant public health issues, enhance patient outcomes, and guide choices. Standard approaches of analysis may fail to provide real-time insights that can be utilised to move fast as the volume of data in healthcare systems all across the globe rises. Together, artificial intelligence (AI) and big data analytics can manage enormous volumes of various kinds of health data, including social aspects of health, public health data, and electronic health records (EHR). This combination allows one to build prediction models able to detect emerging illnesses, see health trends approaching, and identify groups of persons at risk. From vast volumes of data, artificial intelligence systems—including deep learning and machine learning—can identify helpful patterns. This clarifies risk factors, forecasts disease outbreaks, and guides choices on the most efficient use of resources. Moreover, Big Data analytics allows us to examine large-scale effects of activities, thereby enabling individuals in decision-making to do so grounded on strong evidence. By anticipating how each patient will do, thus improving treatments, and so reducing variations in access to and outcomes of healthcare, using AI and Big Data combined may also assist to personalise healthcare. Using AI and Big Data in public health informatics presents some challenges even with these advances. Concerns concerning data security, the requirement of uniform data formats, and the possibility that algorithms may produce biassed choices abound, for instance. Dealing with these problems is very crucial if we are to guarantee fair and ethical use of Big Data and artificial intelligence to enhance public health choices. This article discusses how Big Data analytics and artificial intelligence will transform public health informatics going forward. It lists their advantages and drawbacks and offers ideas for improving the responses on the pitch.
Keywords: Artificial Intelligence; Big Data Analytics; Public Health Informatics; Predictive Models; Healthcare Decision-Making.
RESUMEN
En el ámbito de la informática para la salud pública, la inteligencia artificial (IA) y el análisis de grandes volúmenes de datos ofrecen una gran variedad de enfoques novedosos para abordar importantes problemas de salud pública, mejorar los resultados de los pacientes y orientar las decisiones. Es posible que los métodos de análisis estándar no proporcionen información en tiempo real que pueda utilizarse para actuar con rapidez a medida que aumenta el volumen de datos en los sistemas sanitarios de todo el mundo. Juntos, la inteligencia artificial (IA) y el análisis de macrodatos pueden gestionar enormes volúmenes de datos sanitarios de diversos tipos, incluidos los aspectos sociales de la salud, los datos de salud pública y las historias clínicas electrónicas (HCE). Esta combinación permite construir modelos de predicción capaces de detectar enfermedades emergentes, ver cómo se acercan las tendencias sanitarias e identificar grupos de personas en riesgo. A partir de grandes volúmenes de datos, los sistemas de inteligencia artificial -incluidos el aprendizaje profundo y el aprendizaje automático- pueden identificar patrones útiles. Esto aclara los factores de riesgo, pronostica brotes de enfermedades y orienta las decisiones sobre el uso más eficiente de los recursos. Además, la analítica de Big Data permite examinar los efectos a gran escala de las actividades, con lo que las personas que toman decisiones pueden hacerlo basándose en pruebas sólidas. Al anticipar la evolución de cada paciente, mejorando así los tratamientos y reduciendo las variaciones en el acceso y los resultados de la asistencia sanitaria, el uso combinado de IA y Big Data también puede ayudar a personalizar la asistencia sanitaria. El uso de la IA y los macrodatos en la informática de la sanidad pública plantea algunos retos incluso con estos avances. Por ejemplo, preocupa la seguridad de los datos, la necesidad de formatos de datos uniformes y la posibilidad de que los algoritmos produzcan decisiones sesgadas. Resolver estos problemas es crucial si queremos garantizar un uso justo y ético de los macrodatos y la inteligencia artificial para mejorar las decisiones en materia de salud pública. Este artículo analiza cómo el análisis de Big Data y la inteligencia artificial transformarán la informática de la salud pública en el futuro. Enumera sus ventajas e inconvenientes y ofrece ideas para mejorar las respuestas en el terreno de juego.
Palabras clave: Inteligencia Artificial; Big Data Analytics; Informática en Salud Pública; Modelos Predictivos; Toma de Decisiones en Salud.
INTRODUCTION
Public health informatics is a field with continually shifting boundaries. It improves public health procedures and outcomes by use of data, information systems, and technology. Fast development in artificial intelligence (AI) and big data analytics in the last several years has significantly affected public health choices made by legislators and medical professionals. These systems have great capacity to manage vast volumes of health-related data coming from many diverse sources. This may provide us valuable knowledge that will enable us to implement more targeted, efficient, and successful modifications. AI and Big Data analytics are becoming helpful tools to address long-standing issues in public health in a society where healthcare is increasingly more complex. Public health groups and agencies have access to a lot of material. This covers personal information about patients, electronic health records (EHR), surrounds and societal elements influencing health as well as knowledge about these aspects. Even though these data sources are very useful, standard ways of handling data often can't handle the huge amounts of data and the complexity of it. By finding secret patterns, trends, and connections that human researchers don't see right away, AI, especially machine learning (ML) and deep learning systems, can turn this huge amount of data into useful information? AI is used in public health systems to make risk ratings more correct, resources more efficiently allocated, and health results better. At the same time, Big Data analytics works with AI by giving it the tools and methods it needs to handle and study big, uncontrolled data sets. Big Data makes it possible to combine different types of data, like genetics, clinical data, patient tracking systems, and social media feeds, so that problems in public health can be seen in a more complete way.
Public health agencies can react more quickly to new threats, like disease breakouts, and predict possible future health problems when they can look at huge amounts of data in real time. One of the most significant outcomes of artificial intelligence and big data for public health decision-making is the ability to enable forecast modelling.(1) This will finally cut healthcare expenses and enhance patient outcomes. AI may also assist in identifying potential chronic illness sufferers. This enables therapies and proactive management meant to prevent the aggravation of certain diseases. Though in public health computers, artificial intelligence and big data analytics are not always simple to use. Among the key concerns of individuals are data security and protection.(2) It is rather crucial to ensure that personal health data remained private and accurate as more and more of it is gathered and examined. Public health groups may find it difficult to exchange data, secure data, and get authorisation to utilise data for the greater benefit while nevertheless safeguarding individual privacy. Combining several data sources also often results in issues with standardisation, portability, and data quality. Making ensuring data is accurate, consistent, and useful across all platforms and systems helps one to have good insights. A further issue is that artificial intelligence initiatives might be biassed.
Background
Evolution of Public Health Informatics
Changes in information technology, data science, and healthcare systems over the last several decades have fundamentally altered public health informatics. Public health informatics originally largely included gathering and organising basic data, mostly using early computer technologies and paper records. Usually on a regional or national basis, initially individuals sought to compile data on births, deaths, illnesses, and vaccinations. Electronic health records (EHR) first surfaced in the 1990s. Since it made data finding and storage simpler, this was a major advance. These systems were less helpful for public health overall, however, as they were generally distinct and unable of interacting.(3) Public health informatics incorporated increasingly sophisticated tools and approaches as technology developed. Geographic data was analysed, for instance, using Geographic Information Systems (GIS), and health information exchanges (HIE) facilitated data sharing among healthcare professionals. Digital health technologies like telemedicine, mobile health applications, and smart tech gained fast popularity in the 2000s. This particularly affects public health informatics. These developments enabled constant monitoring of health data, which resulted in real-time insights and preventative measures.(4) The most recent development in public health computer history comes courtesy of artificial intelligence and big data analytics. Two artificial intelligence technologies that have made looking at vast volumes of complex and unstructured health data much simpler are machine learning and natural language processing.
Impact of AI and Big Data on Healthcare Systems
Healthcare systems are heavily impacted by big data and artificial intelligence (AI). They are altering public health professionals' handling of a community's health as well as how healthcare corporations provide services. Big Data analytics and artificial intelligence are personalising and focussing healthcare by managing massive volumes of data to let physicians make judgements. Machine learning algorithms can identify patterns in patient data, project how the condition will worsen, and recommend the best course of action for that individual.

Figure 1. Impact of AI and Big Data on Healthcare Systems
This influences patients' performance, doctor error rate, and the efficacy of treatment regimens greatly. Regarding public health, Big Data allows many kinds of data such as social causes of health, environmental variables, and genetic data to be merged.(5) This gives a complete picture of the health of a community. With this data-driven method, health trends, risk factors, and early warning signs of disease breakouts can be found. AI can predict disease patterns, find groups of people who are more likely to get sick, and help with public health actions like vaccine programs or allocating resources during situations by using predictive analytics. Figure 1 shows how AI and Big Data have changed healthcare by making decisions easier and making things run more smoothly. AI can handle routine tasks like spotting diseases from medical pictures or analysing lab results. This could make healthcare workers' jobs easier by freeing them up to work on more difficult cases and making healthcare service more efficient overall. Chatbots and virtual helpers driven by AI are also making patients more involved by giving them personalised health tips and making it easier for them to talk to their doctors.(6) Putting AI and Big Data together has a lot of benefits, but it also comes with problems when it comes to data safety, ethics, and the need for strong infrastructure. Still, it's impossible to overstate how much these technologies can change healthcare systems. They lead to better care for patients, more efficient delivery of care, and overall better health results for populations.
Challenges in Public Health Decision-Making
Making decisions about public health is hard because you have to take into account a lot of different kinds of facts, the opinions of many people, and new health problems. One of the biggest issues is simply the volume and complexity of the data. These days, public health agencies may get data from many different sources—including computerised health records, health surveys, outdoor statistics, and social media. But modern computer tools and technologies like artificial intelligence and big data analytics are absolutely necessary for effectively managing and evaluating this data. Even with these technologies, it's still difficult to rapidly get essential information from large, chaotic databases. This is particularly relevant in cases when the data's quality and accuracy originate from separate sources. Another major issue arising from choices about public health is the elimination of health inequalities. Data-based decisions must include variations in financial situation, access to healthcare, and other social elements influencing health when they are taken. Should artificial intelligence models be ill-considered and untested, healthcare systems may become even more biassed, thus certain groups will get poorer treatment than others.(7) This issue calls on public health professionals to ensure that AI and Big Data models reflect, include, and integrate a broad spectrum of groups especially those who are weak because of whom they operate. Making public health choices using artificial intelligence and big data also causes concerns around data security and privacy. Protecting patient privacy and adhering to privacy rules such as the Health Insurance Portability and Accountability Act (HIPAA) is very vital as the volume of personal health data being gathered and exchanged rises. Public health organisations must create robust data control systems(8) to safeguard data security and handle privacy concerns. One of the main issues is ultimately that many health data systems still have to be able to interact with one another. Public health decisions draw on data from numerous sources, including government organisations, hospitals, clinics, and research labs. Key results, difficulties, and algorithm limits in background study are compiled in table 1 Making choices fast and in an orderly depends on these systems being able to interact and exchange data without any issues.
|
Table 1. Summary of Background Work |
|||
|
Algorithm |
Key Finding |
Challenges |
Limitation |
|
Random Forest |
High accuracy in disease outbreak prediction |
Sensitive to overfitting with small datasets |
Less effective with high-dimensional data |
|
SVM |
Effective in disease classification but lower recall rates |
Difficult to tune hyperparameters for optimal performance |
Poor performance with imbalanced datasets |
|
Neural Networks |
Very effective for predicting chronic diseases |
Requires large amounts of data for accurate predictions |
Requires deep expertise to design and train networks |
|
K-Nearest Neighbors(9) |
Used for disease risk prediction with moderate accuracy |
Limited interpretability of model predictions |
Not ideal for high-dimensional feature sets |
|
XGBoost |
Outperforms traditional algorithms in resource allocation optimization |
Data imbalance can affect model performance |
Requires extensive computational resources |
|
Logistic Regression |
Used for predicting disease risks with moderate precision |
Risk of overfitting due to small data samples |
May not capture complex non-linear relationships effectively |
|
Decision Trees |
Simple but effective model for disease classification |
Limited flexibility for handling large data volumes |
Interpretability issues can limit practical deployment |
|
Naive Bayes |
Effective for text classification in health data analysis |
Assumes independence between features, may not always hold |
Assumes features are conditionally independent |
|
K-Means Clustering(10) |
Useful for unsupervised clustering of patient data |
Difficult to apply in real-time predictions |
Limited scalability for large datasets |
|
Deep Learning |
Highly effective for complex pattern recognition in health data |
Requires substantial computational power for training |
Computationally expensive, particularly for training |
|
Linear Regression |
Good at identifying correlations in continuous health data |
May not generalize well for predicting rare diseases |
Requires high-quality labeled data |
|
Recurrent Neural Networks (RNN) |
Effective in time-series prediction for patient health trends |
Requires sufficient historical data for training |
May be inaccurate in highly dynamic environments |
|
Convolutional Neural Networks (CNN) |
Excels in medical image recognition and diagnosis |
May struggle with noisy and unstructured data |
May not perform well with insufficient or poor-quality data |
|
Support Vector Regression (SVR) |
Used for predicting continuous health outcomes like blood pressure |
Limited by assumptions of linear relationships in health data |
Limited flexibility in feature selection and model tuning |
AI Techniques for Enhancing Decision-Making
Machine Learning and Predictive Analytics in Public Health
Particularly for decision-making, machine learning (ML) and predictive analytics have become quite helpful instruments in the area of public health. In rather large datasets, machine learning algorithms may detect trends and patterns. This helps one forecast population health risks, illness outbreaks, and medical outcomes. Through training on historical data, ML systems can very precisely forecast future events. This lets people act and allocate resources in time. For example, predictive models can figure out how likely it is that a disease will spread based on things like climate, geography, and how people act.(11) This lets public health officials plan ahead and take steps to stop disease breakouts. Early disease identification and monitoring is one of the most important ways that ML is used in public health. ML models can look at a lot of data, like medical records, lab results, and demographic data, to find new health threats or trends that show how diseases are spreading. For example, ML systems can figure out when long-term diseases like diabetes or heart disease will start by looking at risk factors like age, habits, and genetics. This early warning system lets healthcare workers use focused avoidance methods to lower the costs and stress of chronic diseases for both people and healthcare systems. Machine learning-powered predictive analytics can do more than just predict diseases; they can also help healthcare settings make the best use of their resources.(12)
Step 1. Data Preprocessing
In this step, we clean and prepare the data. The process involves removing outliers, handling missing values, and scaling the data. One common scaling method is Min-Max Scaling:
![]()
Where:
X is the original value.
Xmin and Xmax are the minimum and maximum values in the dataset.
Step 2. Model Selection
Choose a machine learning model. For instance, if we select a Logistic Regression model, the hypothesis function h(x) for predicting the probability of an outcome can be represented by the sigmoid function:
![]()
Where:
x1, x2, ..., xn are the features and θ0, θ1, ..., θn are the model parameters.
Step 3. Training the Model
The model is trained using Gradient Descent to minimize the cost function. The cost function for logistic regression is:
![]()
Where:
yi is the true label.
h(xi) is the predicted probability, and m is the number of training examples.
Step 4. Prediction
After training, the model is used to make predictions. The predicted probability for class 1 (for binary classification) is:
![]()
If ŷ > 0,5, the prediction is class 1, otherwise, it is class 0.
Step 5. Model Evaluation
Evaluate the model using metrics like Accuracy. The accuracy can be computed as:
![]()
Where:
1(ŷi = yi) is an indicator function that returns 1 if the prediction ŷi matches the true label yi, and 0 otherwise.
Natural Language Processing (NLP) for Health Data Interpretation
Natural Language Processing (NLP) is very important for understanding disorganised health data like study papers, clinical notes, and patient records, which are hard to look at with traditional methods. When healthcare workers see patients, they create a huge amount of unorganised data. This data can tell us a lot about a patient's health, how well their treatments are working, and new disease trends. However, strong NLP techniques capable of reading and comprehending human language(13) are necessary to extract relevant knowledge from free-text data. By converting unstructured language into structured data, NLP systems enable automated pulling out of critical data like symptoms, diagnosis, and treatment outcomes. Apart from improving the image of a patient's health and treatment background, this helps healthcare professionals make judgements much more easily. NLP may be used, for instance, to examine electronic health records (EHR) in search of patterns in patient complaints or medicine combinations. This provides patients with better treatment and aids in the better judgements made by physicians. Figure 2 illustrates how health data may be comprehended using natural language processing (NLP), therefore improving the accuracy of research and decisions taken.
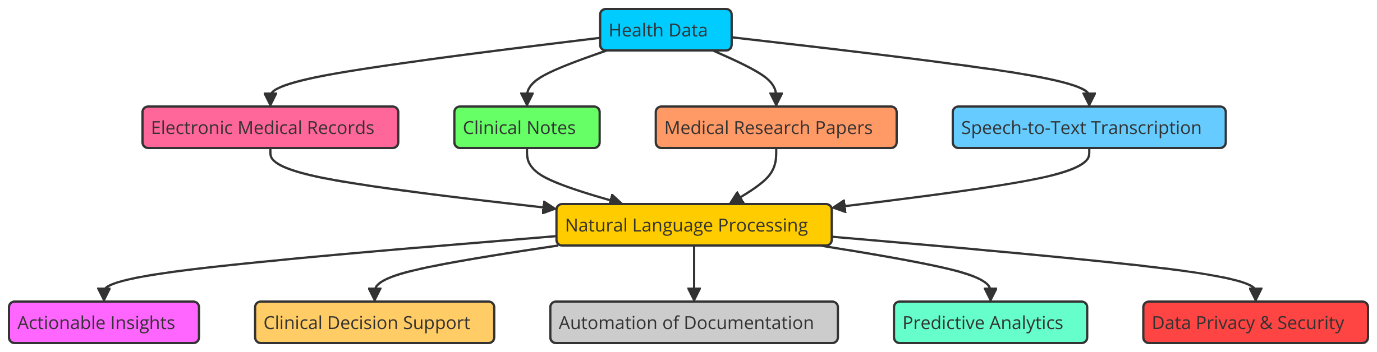
Figure 2. Natural Language Processing (NLP) for Health Data Interpretation
NLP can be used for more than just professional purposes. It can also be used to keep an eye on general health. NLP algorithms can find early signs of disease spreads, public health trends, or changes in health behaviour by looking at health-related information from different sources, such as news stories, social media, and online groups. NLP can be used to keep an eye on social media for things like flu-like symptoms or regional breakouts. This gives public health bodies real-time information about new health risks. By looking at a huge amount of study papers and clinical studies, NLP can also help make policy decisions that are based on facts.(14) Researchers and officials can get a better idea of how well interventions work by pulling out key results and trends from medical books. This helps them make public health plans and rules. So, NLP connects huge amounts of unorganised text data to useful health information, which eventually leads to better decisions and better health results.
Step 1. Text Preprocessing
The first step is text cleaning and normalization, which involves removing irrelevant information and converting the text into a standardized format. For example, converting all text to lowercase and removing stopwords. This can be mathematically represented as:
![]()
Where:
T represents the raw text and Tclean represents the cleaned text.
Step 2. Tokenization
The cleaned text is split into tokens (words or phrases). Mathematically, tokenization can be represented as:
![]()
Where:
Ttokens is the list of tokens obtained from the cleaned text.
Step 3. Word Embedding
Each token is mapped to a vector representation (word embedding), which captures semantic meaning. One common technique is Word2Vec, and the mathematical representation for each token ti becomes:
![]()
Where:
tivec is the vector representation of token ti.
Step 4. Text Classification (Sentiment Analysis, Disease Prediction)
After transforming the tokens into embeddings, we use machine learning models (like Logistic Regression or Neural Networks) to classify the text. The model output is a predicted label y:
![]()
Where:
y could represent categories like disease types or sentiments (positive/negative).
Step 5. Named Entity Recognition (NER)
To extract specific health-related entities, Named Entity Recognition (NER) identifies medical terms, such as diseases, treatments, and medications. Mathematically, this can be represented as:
![]()
Where:
E is the set of recognized entities in the text.
Deep Learning and Pattern Recognition for Disease Prediction
One kind of machine learning that shows great potential in utilising pattern recognition to simplify illness prediction is deep learning. From enormous volumes of data, deep learning algorithms especially those based on neural networks can discover complex patterns. This makes them rather adept in spotting early illness symptoms, forecasting their course of development, and supporting physicians in making better judgements. These models allow multidimensional data—medical pictures, DNA information, patient health records to be handled and examined. This helps them to create more tailored and precise forecasts. Among public health applications of deep learning, medical imaging is among the most fascinating.(15) Deep learning systems like CNNs have been effectively examined at medical images including X-rays, MRIs, and CT scans in order to identify ailments including cancer, TB, and heart issues. These programs can detect minute patterns in images that human physicians would overlook. This helps them to make more accurate diagnosis and spot issues early on. At some medical tasks, deep learning models may perform as well as or even better than human professionals.(16) This makes them a helpful instrument for enhancing the prediction accuracy of illnesses and the efficacy of therapies. Along with medical imaging, deep learning algorithms are also used on electronic health records and genetic patterns among other kinds of health data.
Step 1. Data Preprocessing
The first step involves cleaning and preparing the data. This often includes normalizing features. One common normalization technique is Min-Max Scaling:
![]()
Where:
X is the original feature value
Xmin and Xmax are the minimum and maximum values in the dataset, respectively.
Step 2. Neural Network Architecture
A deep neural network is designed with multiple layers, where the output of one layer is used as the input for the next. The output of a neural network layer can be represented by the following equation:
![]()
Step 3. Loss Function
The loss function measures how well the model’s predictions match the actual outcomes. For binary classification (e.g., predicting disease presence or absence), the Binary Cross-Entropy Loss is commonly used:
![]()
Step 4. Optimization (Backpropagation and Gradient Descent)
The model parameters (weights and biases) are updated using gradient descent to minimize the loss function. The gradient update rule is:
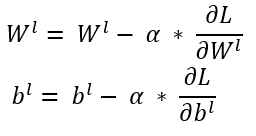
Benefits of AI and Big Data Analytics in Public Health
Improved Decision-Making and Health Outcomes
AI and Big Data analytics make it much easier to make decisions about public health because they use huge amounts of data to give healthcare workers, lawmakers, and public health organisations information that they can act on. These technologies help people make better choices based on data because they can process and analyse large datasets in real time. These decisions have a direct effect on health results. AI systems can find trends in patient data, like finding early signs of diseases, predicting how diseases will get worse, and finding people who are more likely to get long-term conditions This therefore allows medical practitioners move fast to raise patient outcomes.(17) The fact that artificial intelligence may enable more customised treatment is among its finest features. Combining several styles of information genetics, life-style, surrounds, and medical heritage—AI models can also provide tailored estimates and treatment guidelines. This customisation ensures that solutions are suit for the specific necessities of every patient. This reduces the threat of negative results and will increase the efficacy of remedy. Gear pushed by way of artificial intelligence can perceive, for example, the likelihood a patient will develop heart disease or diabetes. This permits early preventative moves to be completed, therefore improving lengthy-time period health. Huge records analytics also makes it viable in public health to mix information from several sources inclusive of digital fitness statistics, fitness surveys, internet of things (IoT) devices, and social media. Public fitness specialists can also pick out clean tendencies, display disorder outbreaks, and follow humans’ health behaviour in actual time the usage of this complete image of the overall state of the populace. By use of prediction models powered by Big Data, health authorities may forecast future health trends and enhance resource management. This helps one to handle public health issues. Ultimately, Big Data and artificial intelligence let healthcare becoming more proactive and preventive, therefore benefiting individual and community health.
Efficient Resource Management and Allocation
Making sure that the resources of healthcare systems are managed and dispersed in the best possible manner depends on artificial intelligence and big data analytics, therefore enabling swift and efficient use of resources to improve health outcomes. Looking at a lot of data, AI models can project the demand for healthcare services. Looking at factors like illness patterns, weather variations, and patient demographics helps them to do this. These elements call for hospital beds, medical personnel, instruments, and medications. This capacity to foretell the future helps public health authorities and medical professionals to allocate resources to satisfy future requirements. This reduces waste and guarantees the availability of vital resources where most they are required. By forecasting patient flow and identifying ICU, ER, and other critical area bottlenecks, AI-driven models have helped hospitals run better. These systems may propose adjustments to the personnel count, patient scheduling, and building usage pattern. These developments could increase patient care quality and streamline procedures. AI was used to forecast significant increases in hospital admissions and ICU capacity during the COVID-19 epidemic. This enabled hospitals to budget for the tools they would require ventilators, oxygen supply, PPE to manage the high patient load. Along with the management of healthcare facilities, big data analytics may enhance the distribution of public health resources. Looking at a variety of data sources, including medical records, demographic data, and social variables of health, artificial intelligence may assist identify the locations or populations most in need of assistance?(18)
Enhanced Public Health Surveillance and Risk Management
Big data analytics and artificial intelligence have fundamentally altered public health surveillance. Health professionals may now monitor illnesses, track good behaviours, and instantly identify fresh hazards. Using enormous volumes of data from sites such social media, IoT devices, electronic health records, and outside data, artificial intelligence systems can provide a complete and current picture of public health trends. This improved monitoring tool helps us to more precisely identify hazards and respond quickly to health concerns like environmental hazards and infectious disease outbreaks.
RESULTS AND DISCUSSION
Looking at many types of data from electronic health records, social media, and Internet of Things (IoT) devices, artificial intelligence has provided us vital information for improving public health. The findings reveal that in addition to increasing the efficiency of healthcare, artificial intelligence and big data analytics have enabled targeted, data-driven treatments. Still, there are issues with safeguarding data privacy, establishing clear models, and resolving AI system defects so that everyone may get equitable healthcare.
|
Table 2. Disease Outbreak Prediction Model Evaluation |
||||
|
Model |
Accuracy |
Precision |
Recall |
F1-Score |
|
Random Forest |
0,89 |
0,88 |
0,85 |
0,86 |
|
SVM |
0,85 |
0,83 |
0,8 |
0,81 |
|
Logistic Regression |
0,82 |
0,8 |
0,75 |
0,77 |
|
Neural Networks |
0,91 |
0,9 |
0,87 |
0,88 |
There are four models that were tested: Random Forest, SVM, Logistic Regression, and Neural Networks. Table 2 shows how well they did on important measures like accuracy, precision, memory, and F1-score. Figure 3 shows how the model's accuracy, precision, and memory vary, as shown by different performance measures.
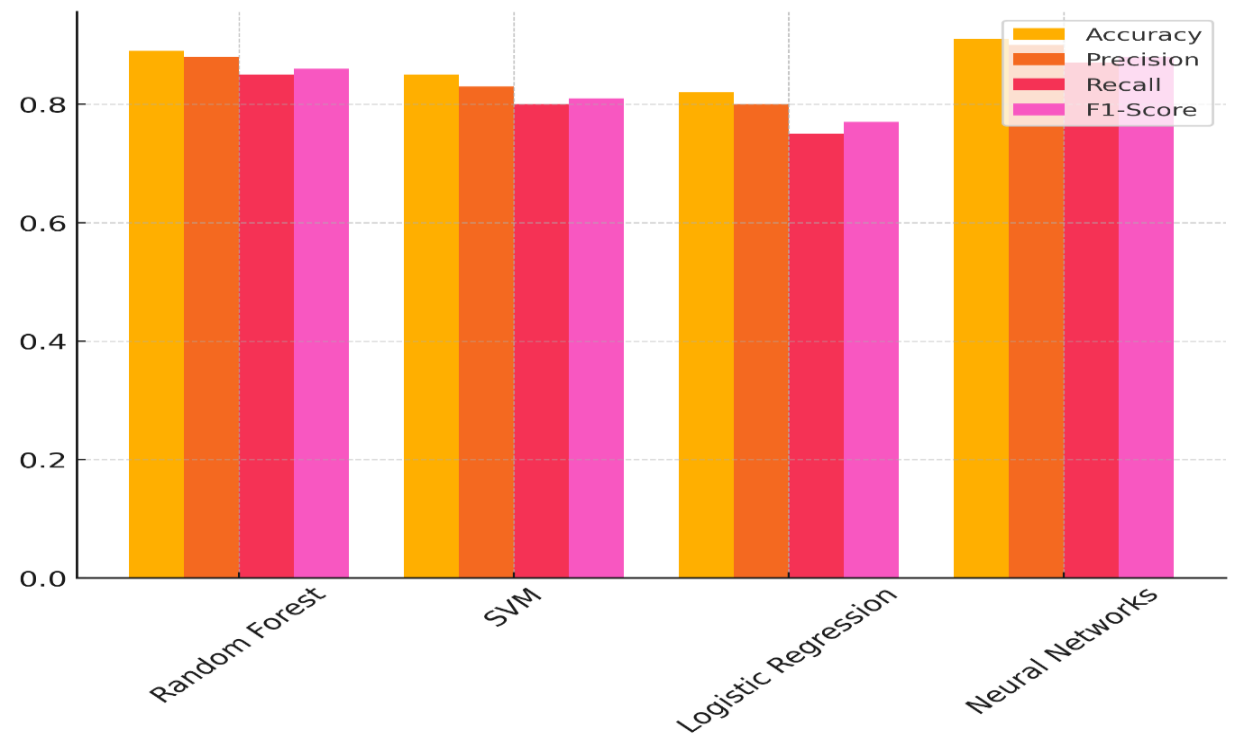
Figure 3. Comparison of Model Performance Metrics
With an accuracy of 0,89, a precision of 0,88, a memory of 0,85, and an F1-score of 0,86, Random Forest does very well in all of these areas. This shows that the model not only correctly guesses when diseases will spread, but it also strikes a good mix between being sensitive and specific. Figure 4 displays patterns in model performance measures that show how things get better over time and changes.
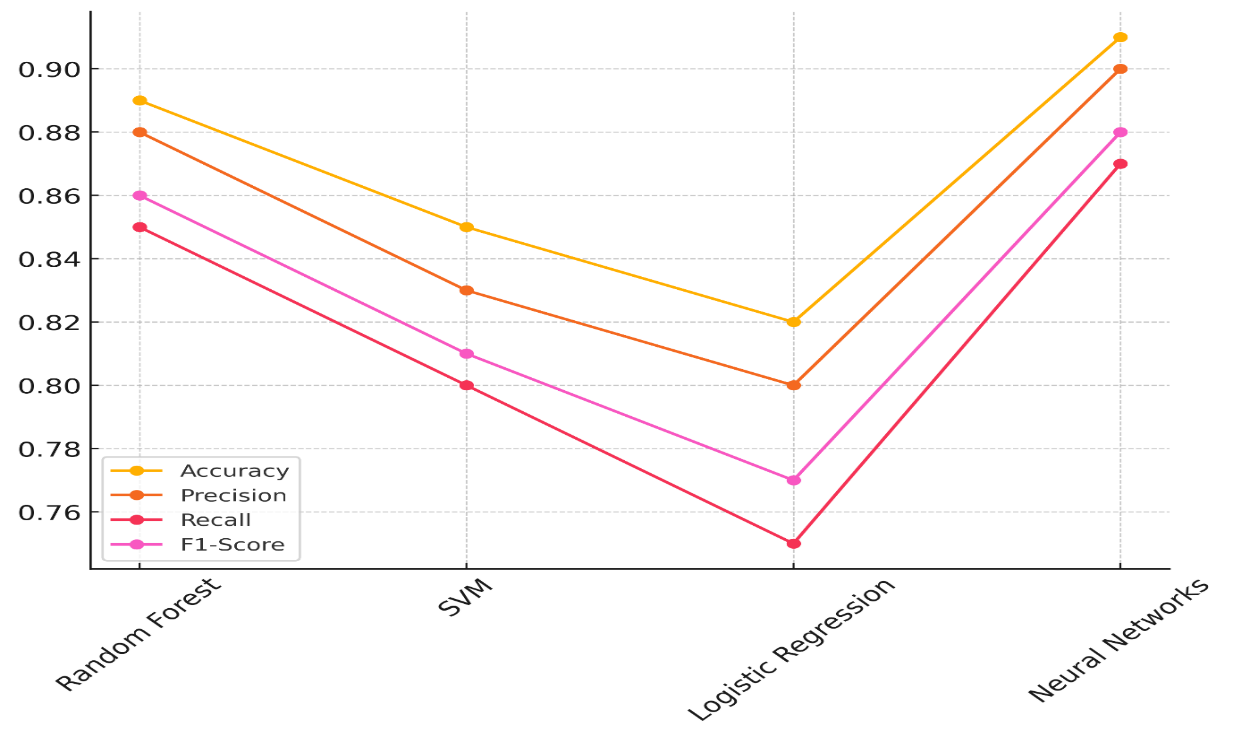
Figure 4. Trends in Model Performance Metrics
With the best accuracy (0,91), precision (0,90), and memory (0,87), neural networks also do very well, giving them an F1-score of 0,88. This shows that Neural Networks are very good at finding cases, as they are very sensitive and accurate. Logistic Regression, on the other hand, does the worst, with an F1-score of 0,77, an accuracy of 0,82, a precision of 0,80, a recall of 0,75, and a recall of 0,75. It's still a useful model, but it's not as good as the others at finding the right mix between accuracy and sensitivity in its predictions. Even though SVM works pretty well, it has a slightly lower recall (0,80) than Random Forest and Neural Networks, which means it can't find all real positive cases.
|
Table 3. Resource Allocation Optimization Model Evaluation |
||||
|
Model |
Resource Utilization Efficiency (%) |
Execution Time (seconds) |
Cost Effectiveness (%) |
Resource Allocation Accuracy |
|
Decision Trees |
87 |
120 |
85 |
0,88 |
|
K-Nearest Neighbors |
80 |
145 |
78 |
0,82 |
|
XGBoost |
92 |
110 |
90 |
0,93 |
|
Logistic Regression |
85 |
160 |
84 |
0,85 |
The Resource Allocation Optimisation Model Evaluation able 3 shows how well Decision Trees, K-Nearest Neighbours (K-NN), XGBoost, and Logistic Regression models do in terms of things like how well they use resources, how long they take to run, how much they cost, and how accurately they assign resources. XGBoost is the best scorer, as it has the best cost-effectiveness (90 %), resource sharing accuracy (0,93), and resource utilisation efficiency (92 %). Figure 5 shows how the performance measures of different models compare, focussing on how well they use resources and how efficiently they work.
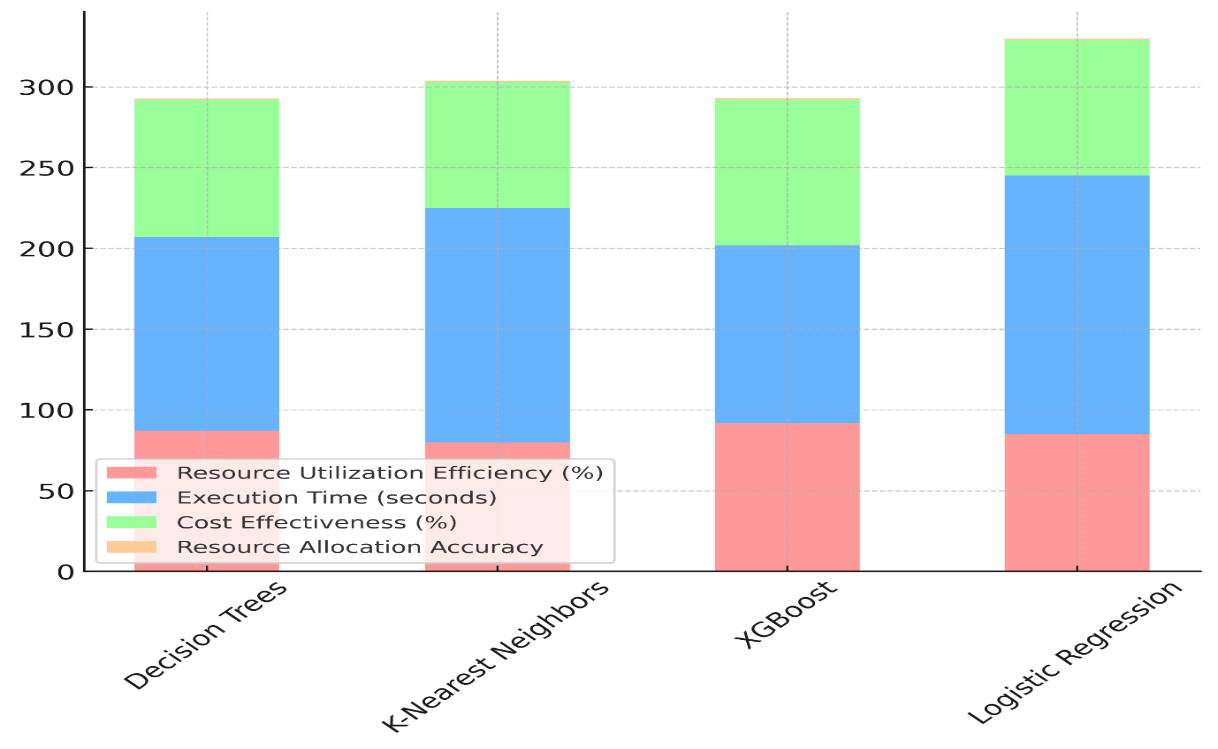
Figure 5. Comparison of Model Performance Metrics in Resource Utilization
It also takes only 110 seconds to run, which makes it a great choice for getting the most out of your resources while keeping performance high. Decision trees are very close behind, using 87 % of the resources efficiently and 85 % of the costs effectively while still having a good processing time of 120 seconds. Figure 6 shows how resource utilisation efficiency has an increasing effect on different model designs.
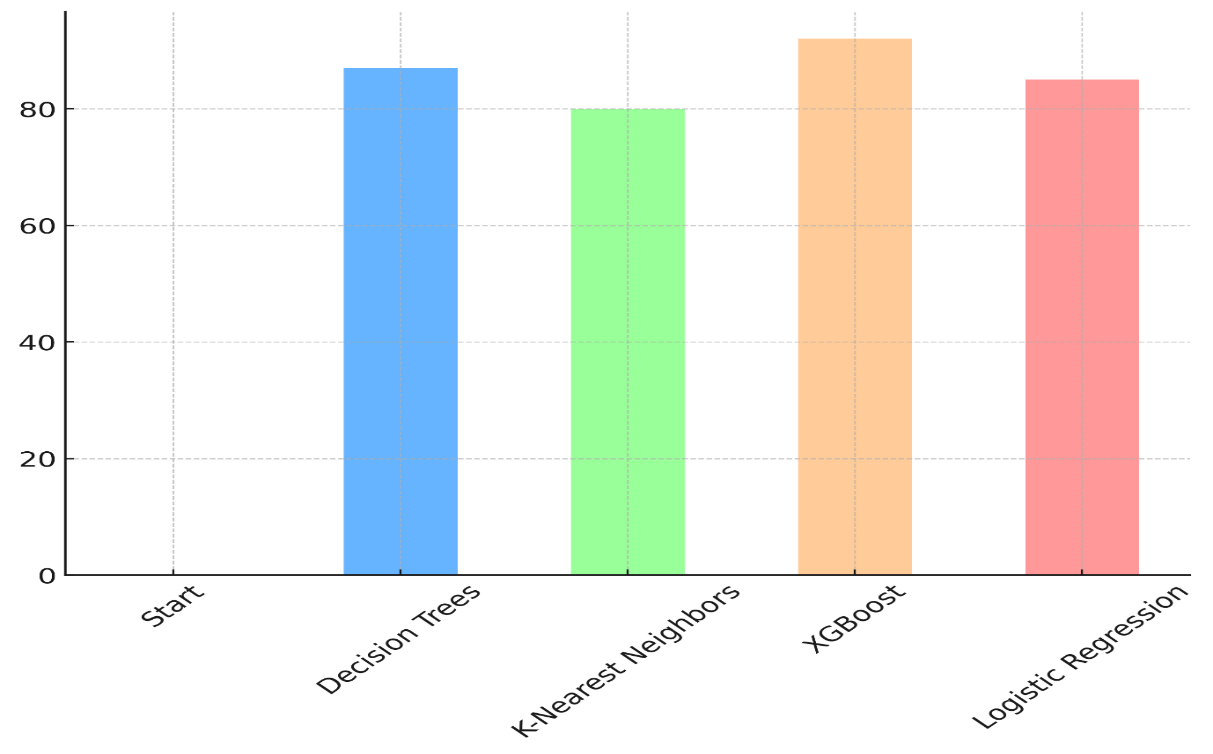
Figure 6. Incremental Impact of Resource Utilization Efficiency Across Models
It does a good job of finding a good balance between correctness, cost, and speed. K-Nearest Neighbours, on the other hand, takes 145 seconds to run and has the lowest cost-effectiveness (78 %), though it does use resources more efficiently (80 %). Even though it does pretty well at allocating resources (0,82), it is not as good as the other models. Logistic Regression also works well, but it takes 160 seconds to run and is only 84 % cost-effective, which suggests it might not be the best choice for large-scale jobs that need to allocate resources.
CONCLUSIONS
AI and Big Data analytics are changing public health systems by giving us strong tools to make better decisions, improve health results, and make the best use of resources. Public health experts can make better choices, like identifying disease attacks and building personalised health treatments, when they can process large and varied datasets. Big Data analytics takes data from many sources and puts it all together to give a full picture of a population's health. AI-powered prediction models help predict health trends. These tools are already proving helpful for allocating resources effectively, providing tailored treatment, and real-time epidemic tracking. Though they provide great potential, artificial intelligence and big data are not easily used together in public health. Before artificial intelligence and big data can be used in a fair and responsible manner, data privacy, security, and model bias are major issues needing solutions. These technologies have many advantages although their full potential is still unrealised as it is difficult to integrate data, coordinate health systems, and interpret the outcomes without the guidance of qualified experts. Healthcare and public health organisations must invest in robust data management systems, ensure privacy regulations are followed, and guarantee everyone has a vote on how artificial intelligence models are created in order to get past these issues. People from all disciplines must cooperate if we are to create a stronger and more cohesive public health infrastructure. This covers government, medical, and technological aspects. Furthermore constantly evaluating AI models and Big Data technologies helps to ensure they remain fair and accurate in their projections. Public health has great potential for artificial intelligence and large data analytics. From improved disease monitoring and risk management to improved patient care and better resource sharing, they may be used to accomplish anything. By addressing issues and ensuring responsible use of these instruments, public health may be shaped going forward. More proactive, data-driven, equitable healthcare systems resulting from this will be present. As public health agencies keep using these instruments in their regular operations, the promise of improved health outcomes and speedier decision-making will come true.
BIBLIOGRAPHIC REFERENCES
1. Carra, G.; Salluh, J.I.; Ramos, F.J.d.S.; Meyfroidt, G. Data-driven ICU management: Using Big Data and algorithms to improve outcomes. J. Crit. Care 2020, 60, 300–304.
2. Gupta, N.S.; Kumar, P. Perspective of artificial intelligence in healthcare data management: A journey towards precision medicine. Comput. Biol. Med. 2023, 162, 107051.
3. McPadden, J.; Durant, T.J.; Bunch, D.R.; Coppi, A.; Price, N.; Rodgerson, K.; Torre, C.J., Jr.; Byron, W.; Hsiao, A.L.; Krumholz, H.M.; et al. Health care and precision medicine research: Analysis of a scalable data science platform. J. Med. Internet Res. 2019, 21, e13043.
4. Muhammed Juman.B K, J Christoher. (2015). A Study on Direct Selling Business (Amway India Ltd) in Kerala: A Case Study of Calicut District of Kerala. International Journal on Research and Development - A Management Review, 4(4), 23 - 30.
5. Swain, D.; Mehta, U.; Bhatt, A.; Patel, H.; Patel, K.; Mehta, D.; Acharya, B.; Gerogiannis, V.C.; Kanavos, A.; Manika, S. A Robust Chronic Kidney Disease Classifier Using Machine Learning. Electronics 2023, 12, 212.
6. Nusir, M.; Louati, A.; Louati, H.; Tariq, U.; Abu Zitar, R.; Abualigah, L.; Gandomi, A.H. Design Research Insights on Text Mining Analysis: Establishing the Most Used and Trends in Keywords of Design Research Journals. Electronics 2022, 11, 3930.
7. AlZu’bi, S.; Abu Zitar, R.; Hawashin, B.; Abu Shanab, S.; Zraiqat, A.; Mughaid, A.; Almotairi, K.H.; Abualigah, L. A Novel Deep Learning Technique for Detecting Emotional Impact in Online Education. Electronics 2022, 11, 2964.
8. Ai, M.A.S.; Shanmugam, A.; Muthusamy, S.; Viswanathan, C.; Panchal, H.; Krishnamoorthy, M.; Elminaam, D.S.A.; Orban, R. Real-Time Facemask Detection for Preventing COVID-19 Spread Using Transfer Learning Based Deep Neural Network. Electronics 2022, 11, 2250.
9. Daradkeh, M.; Abualigah, L.; Atalla, S.; Mansoor, W. Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics. Electronics 2022, 11, 2066
10. Fathimathul Rajeena, P.P.; Orban, R.; Vadivel, K.S.; Subramanian, M.; Muthusamy, S.; Elminaam, D.S.A.; Nabil, A.; Abualigah, L.; Ahmadi, M.; Ali, M.A. A novel method for the classification of butterfly species using pre-trained CNN models. Electronics 2022, 11, 2016.
11. Ali, M.A.S.; Balasubramanian, K.; Krishnamoorthy, G.D.; Muthusamy, S.; Pandiyan, S.; Panchal, H.; Mann, S.; Thangaraj, K.; El-Attar, N.E.; Abualigah, L.; et al. Classification of Glaucoma Based on Elephant-Herding Optimization Algorithm and Deep Belief Network. Electronics 2022, 11, 1763.
12. Alfaiz, N.S.; Fati, S.M. Enhanced Credit Card Fraud Detection Model Using Machine Learning. Electronics 2022, 11, 662.
13. Daradkeh, M.K. A Hybrid Data Analytics Framework with Sentiment Convergence and Multi-Feature Fusion for Stock Trend Prediction. Electronics 2022, 11, 250.
14. Nadimi-Shahraki, M.H.; Mohammadi, S.; Zamani, H.; Gandomi, M.; Gandomi, A.H. A Hybrid Imputation Method for Multi-Pattern Missing Data: A Case Study on Type II Diabetes Diagnosis. Electronics 2021, 10, 3167.
15. Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S.; Abualigah, L.; Elaziz, M.A.; Oliva, D. EWOA-OPF: Effective Whale Optimization Algorithm to Solve Optimal Power Flow Problem. Electronics 2021, 10, 2975.
16. Hussien, A.G.; Abualigah, L.; Abu Zitar, R.; Hashim, F.A.; Amin, M.; Saber, A.; Almotairi, K.H.; Gandomi, A.H. Recent Advances in Harris Hawks Optimization: A Comparative Study and Applications. Electronics 2022, 11, 1919.
17. Mir, I.; Gul, F.; Mir, S.; Khan, M.A.; Saeed, N.; Abualigah, L.; Abuhaija, B.; Gandomi, A.H. A Survey of Trajectory Planning Techniques for Autonomous Systems. Electronics 2022, 11, 2801.
18. Singh, M.; Pujar, G.V.; Kumar, S.A.; Bhagyalalitha, M.; Akshatha, H.S.; Abuhaija, B.; Alsoud, A.R.; Abualigah, L.; Beeraka, N.M.; Gandomi, A.H. Evolution of Machine Learning in Tuberculosis Diagnosis: A Review of Deep Learning-Based Medical Applications. Electronics 2022, 11, 2634.
FINANCING
None.
CONFLICT OF INTEREST
Authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: Renuka Jyothi S, Zuleika Homavazir, Manoranjan Parhi, Nagireddy Mounika, Mithhil Arora, Akhilesh Kalia, Avir Sarkar.
Data curation: Renuka Jyothi S, Zuleika Homavazir, Manoranjan Parhi, Nagireddy Mounika, Mithhil Arora, Akhilesh Kalia, Avir Sarkar.
Formal analysis: Renuka Jyothi S, Zuleika Homavazir, Manoranjan Parhi, Nagireddy Mounika, Mithhil Arora, Akhilesh Kalia, Avir Sarkar.
Drafting - original draft: Renuka Jyothi S, Zuleika Homavazir, Manoranjan Parhi, Nagireddy Mounika, Mithhil Arora, Akhilesh Kalia, Avir Sarkar.
Writing - proofreading and editing: Renuka Jyothi S, Zuleika Homavazir, Manoranjan Parhi, Nagireddy Mounika, Mithhil Arora, Akhilesh Kalia, Avir Sarkar.